Hàm kích hoạt¶
Hàm tuyến tính¶
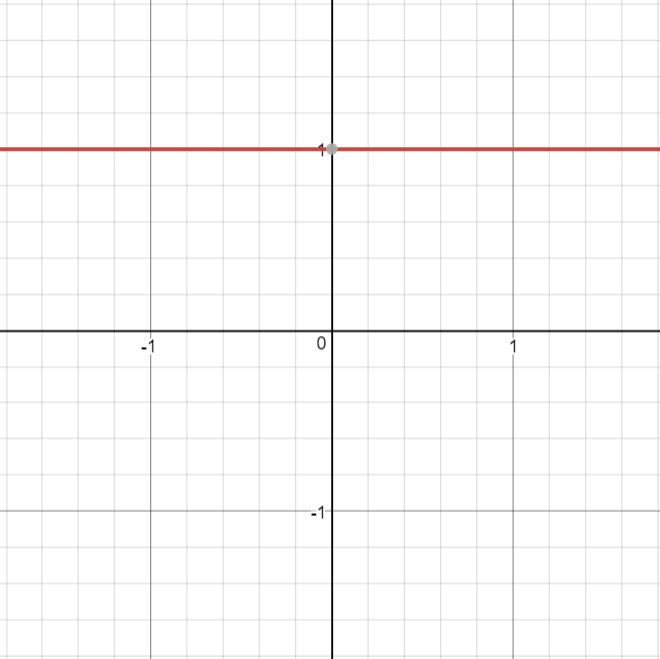
Hàm một đường thẳng trong đó đầu ra kích hoạt tỉ lệ với đầu vào (tức là tổng có trọng số tại nơ-ron).
Hàm số |
Đạo hàm |
\[\begin{split}R(z,m) = \begin{Bmatrix} z*m \\
\end{Bmatrix}\end{split}\]
|
\[\begin{split}R'(z,m) = \begin{Bmatrix} m \\
\end{Bmatrix}\end{split}\]
|

|
|
def linear(z, m):
return m*z
|
def linear_prime(z, m):
return m
|
Ưu điểm
Hàm trả về kích hoạt trong 1 khoảng giá trị, vì vậy nó không phải kích hoạt nhị phân.
Ta hoàn toàn có thể liên kết 1 vài nơ-ron với nhau và nếu nhiều hơn 1 nơ-ron được kích hoạt, ta có thể lấy giá trị lớn nhất (hoặc đưa qua hàm softmax) và dựa vào đó để đưa ra quyết định.
Nhược điểm
Với hàm này, đạo hàm là một hằng số, nghĩa là gradient không có bất cứ mối quan hệ nào với đầu vào \(X\).
Gradient của hàm này cũng là hằng số, và có nghĩa là quá trình hạ gradient được thực hiện trên một gradient có dạng hằng số.
Khi có lỗi dự đoán, các cập nhật được thực hiện bởi lan truyền ngược là hằng số và không phụ thuộc vào sự biến thiên của đầu vào \(delta(x)\)!
ReLU - Đơn vị chỉnh lưu tuyến tính¶
ReLU là viết tắt cho đơn vị chỉnh lưu tuyến tính (Rectified Linear Unit), một trong những phát minh gần đây và vô cùng phổ biến trong thiết kế và xây dựng mạng nơ-ron nhân tạo. Mặc dù có "tuyến tính" trong tên gọi, ReLU không phải là hàm tuyến tính và có chức năng giống như Sigmoid (nghĩa là giúp mạng có khả năng học các hàm phi tuyến), nhưng với hiệu năng tốt hơn.
Hàm số |
Đạo hàm |
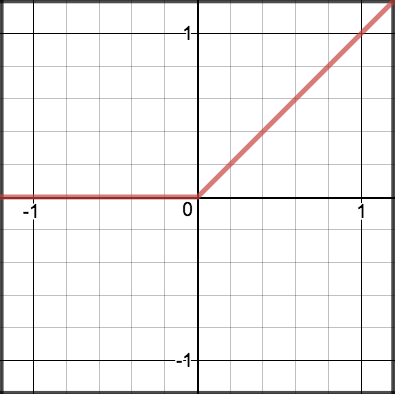
\[\begin{split}R(z) = \begin{Bmatrix} z & z > 0 \\
0 & z <= 0 \end{Bmatrix}\end{split}\]
|
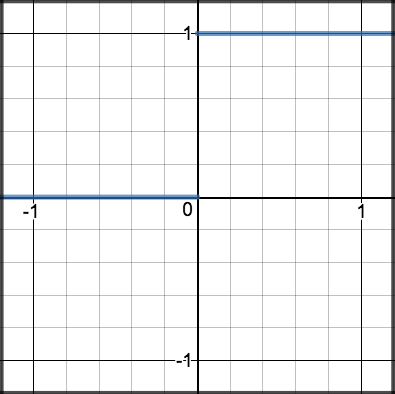
\[\begin{split}R'(z) = \begin{Bmatrix} 1 & z>0 \\
0 & z<0 \end{Bmatrix}\end{split}\]
|
|
|
def relu(z):
return max(0, z)
|
def relu_prime(z):
return 1 if z > 0 else 0
|
Ưu điểm
Giúp tránh bị vấn đề tan biến gradient.
ReLU có độ phức tạp tính toán thấp hơn Tanh hay Sigmoid do nó chỉ yêu cầu các thao tác đơn giản hơn nhiều về mặt toán học.
Nhược điểm
Một trong những hạn chế của ReLU là nó chỉ nên được dùng trong các tầng ẩn của một mạng nơ-ron, không phải tầng đầu ra.
Một số nơ-ron có thể bị chết trong quá trình huấn luyện, tức là nó có thể khiến một nơ-ron có trọng số luôn trả về kết quả âm sẽ không bao giờ được kích hoạt dù đầu vào có là gì đi chăng nữa (do đầu ra của RelU lúc đó sẽ bằng \(0\)).
Nói một cách khác, với các kích hoạt trong khoảng \(x < 0\) của ReLU, gradient sẽ luôn bằng \(0\) và do đó trọng số sẽ không được cập nhật trong quá trình hạ gradient. Điều này có nghĩa là các nơ-ron mà có trạng thái đó sẽ không phản ứng lại với sự biến thiên của đầu vào / lỗi dự đoán (đơn giản là do gradient bằng \(0\) thì chẳng có gì thay đổi cả). Hiện tượng này có tên gọi là dying ReLU.
Khoảng giá trị trả về của ReLU là \([0, \infty)\), có nghĩa là giá trị kích hoạt có thể bị bùng nổ (exploding gradient).
Tài liệu khác
Deep Sparse Rectifier Neural Networks Glorot et al., (2011)
Yes You Should Understand Backprop, Karpathy (2016)
ELU - Exponential Linear Unit¶
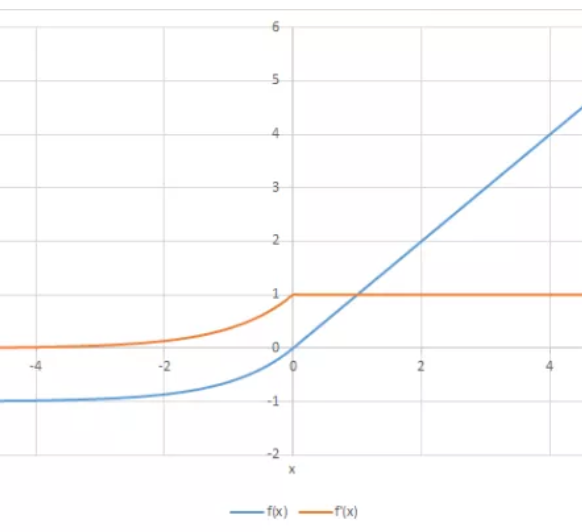
ELU là một hàm số có xu hướng giúp chi phí hội tụ về 0 nhanh hơn và do đó đưa ra kết quả chính xác hơn. Khác với các hàm kích hoạt khác, ELU có một hằng số dương \(\alpha\).
So với ReLU - Đơn vị chỉnh lưu tuyến tính, ELU khá tương đồng, ngoại trừ với đầu vào âm. Cả hai hàm kích hoạt đều là hàm đồng nhất với đầu vào không âm, nhưng với đầu vào âm, ELU trở thành một đường trơn và đầu ra tiến tới \(-\alpha\) khi đầu vào tiến tới \(-\infty\), trong khi ReLU tạo ra 1 đoạn đồ thị gấp khúc.
Hàm số |
Đạo hàm |
\[\begin{split}R(z) = \begin{Bmatrix} z & z > 0 \\
\alpha.( e^z – 1) & z \leqslant 0 \end{Bmatrix}\end{split}\]
|
\[\begin{split}R'(z) = \begin{Bmatrix} 1 & z>0 \\
\alpha.e^z & z<0 \end{Bmatrix}\end{split}\]
|

|
|
def elu(z, alpha):
return z if z >= 0 else alpha*(np.exp(z) - 1)
|
def elu_prime(z, alpha):
return 1 if z > 0 else alpha*np.exp(z)
|
Ưu điểm
ELU là hàm trơn và dần tiến đến \(-\alpha\) trong khi ReLU có đồ thị gấp khúc.
ELU là một phương án thay thế tốt so với ReLU.
Không như ReLU, ELU có thể trả về đầu ra âm.
Nhược điểm
Với \(x > 0\), đầu ra kích hoạt của ELU có thể bị bùng nổ do đầu ra nằm trong khoảng \([0, \infty)\)
Leaky ReLU - ReLU rò rỉ¶
LeakyRelu là một biến thể của ReLU. Thay vì trực tiếp trả về giá trị \(0\) khi \(z < 0\), một đơn vị rò rỉ cho phép một hằng số gradient rất nhỏ, khác không \(\alpha\) (thông thường \(\alpha = 0.01\)). Tuy nhiên, lợi ích của việc rò rỉ ReLU khi sử dụng trong nhiều tác vụ khác nhau khá bất ổn. 1
Hàm số |
Đạo hàm |
\[\begin{split}R(z) = \begin{Bmatrix} z & z > 0 \\
\alpha z & z \leqslant 0 \end{Bmatrix}\end{split}\]
|
\[\begin{split}R'(z) = \begin{Bmatrix} 1 & z>0 \\
\alpha & z<0 \end{Bmatrix}\end{split}\]
|

|
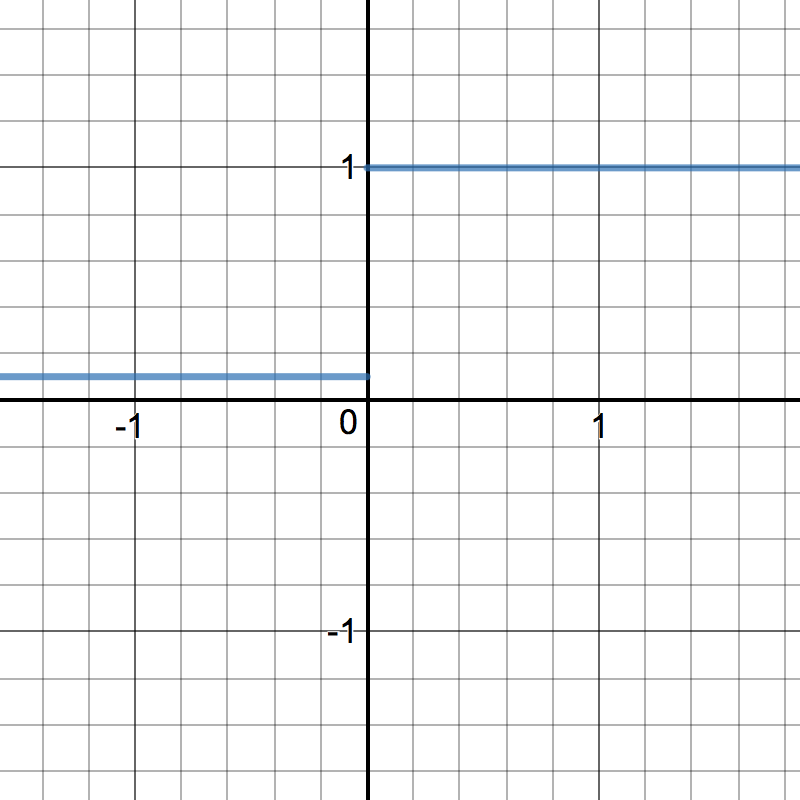
|
def leakyrelu(z, alpha):
return max(alpha * z, z)
|
def leakyrelu_prime(z, alpha):
return 1 if z > 0 else alpha
|
Ưu điểm
ReLU rò rỉ là một trong những biện pháp giúp giải quyết vấn đề "dying ReLU" bằng cách có một độ dốc âm rất nhỏ (khoảng \(0.01\) hoặc tương tự).
Nhược điểm
Do có tính tuyến tính tại các khoảng giá trị khác nhau, hàm này không thể được sử dụng cho bài toán phân loại phức tạp. Nó kém hơn Sigmoid hay Tanh trong một số ứng dụng nhất định.
Tài liệu khác
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, Kaiming He et al. (2015)
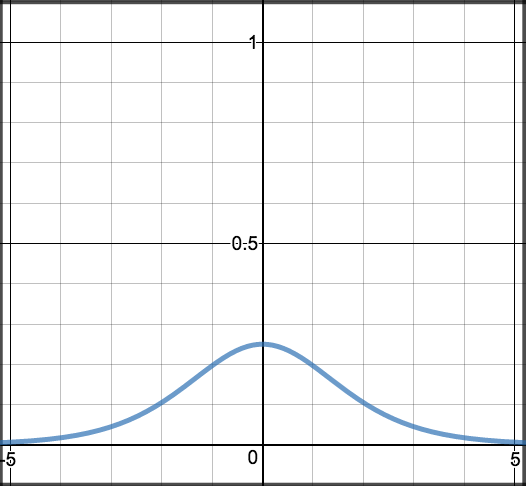
Sigmoid¶
Sigmoid nhận đầu vào là một giá trị thực và trả về một giá trị trong khoảng từ \(0\) đến \(1\). Hàm này khá đơn giản và có các tính chất cần thiết của một hàm kích hoạt: phi tuyến, là hàm đơn điệu, liên tục và khả vi, và đầu ra có khoảng giá trị cố định.
Hàm số |
Đạo hàm |
\[S(z) = \frac{1} {1 + e^{-z}}\]
|
\[S'(z) = S(z) \cdot (1 - S(z))\]
|

|
|
def sigmoid(z):
return 1.0 / (1 + np.exp(-z))
|
def sigmoid_prime(z):
return sigmoid(z) * (1-sigmoid(z))
|
Ưu điểm
Là một hàm phi tuyến trong tự nhiên, và các hàm hợp của hàm này cũng phi tuyến.
Trả về một kích hoạt tương tự không như hàm bước nhảy (trả về kích hoạt số).
Có gradient trơn.
Phù hợp với các bộ phân loại.
Đầu ra của hàm luôn trong khoảng \((0, 1)\) so với \((-\infty, \infty)\) của hàm tuyến tính, tức là ta có được các kích hoạt bị giới hạn trong một khoảng. Điều này sẽ giúp mạnh tránh bị bùng nổ gradient.
Nhược điểm
Khi càng tiến xa về 2 phía của hàm Sigmoid, giá trị \(y\) phản ứng lại càng ít khi \(x\) thay đổi.
Có thể dễ dàng gặp phải vấn đề tiêu biến gradient (vanishing gradient).
Đầu ra của hàm có trung bình khác không. Việc này khiến cho việc cập nhật gradient sẽ bị thiên quá nhiều về một hướng, khiến cho việc tối ưu khó khăn hơn 2.
Hàm Sigmoid có thể bão hoà, mạng từ chối việc tiếp tục học hoặc việc học trở nên vô cùng chậm (tuỳ vào ứng dụng và liệu việc tính gradient có bị hạn chế bởi giới hạn biểu diễn số có dấu phẩy động).
Tài liệu khác
Yes You Should Understand Backprop, Karpathy (2016)
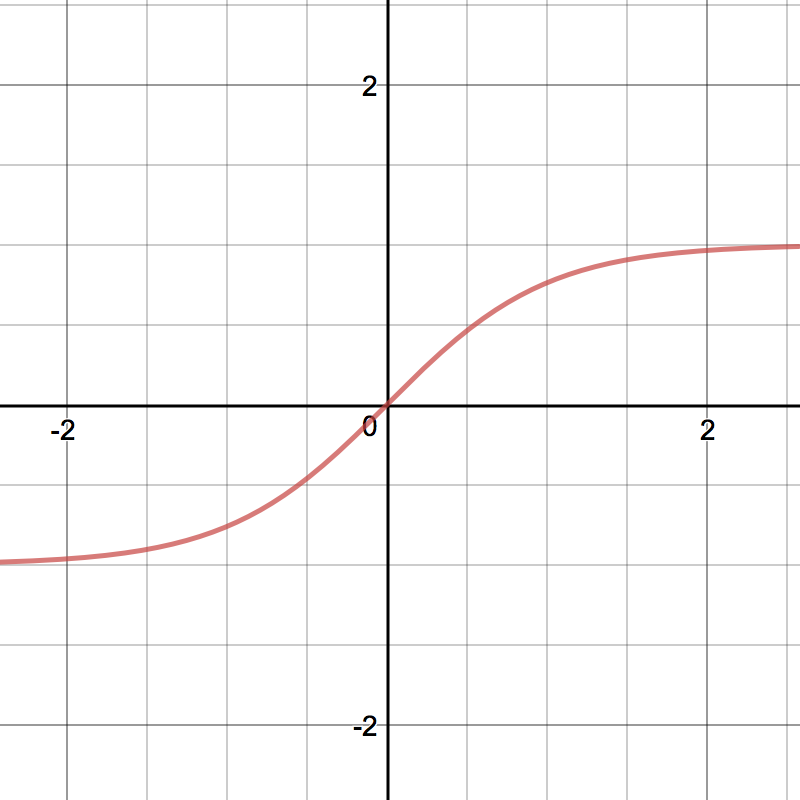
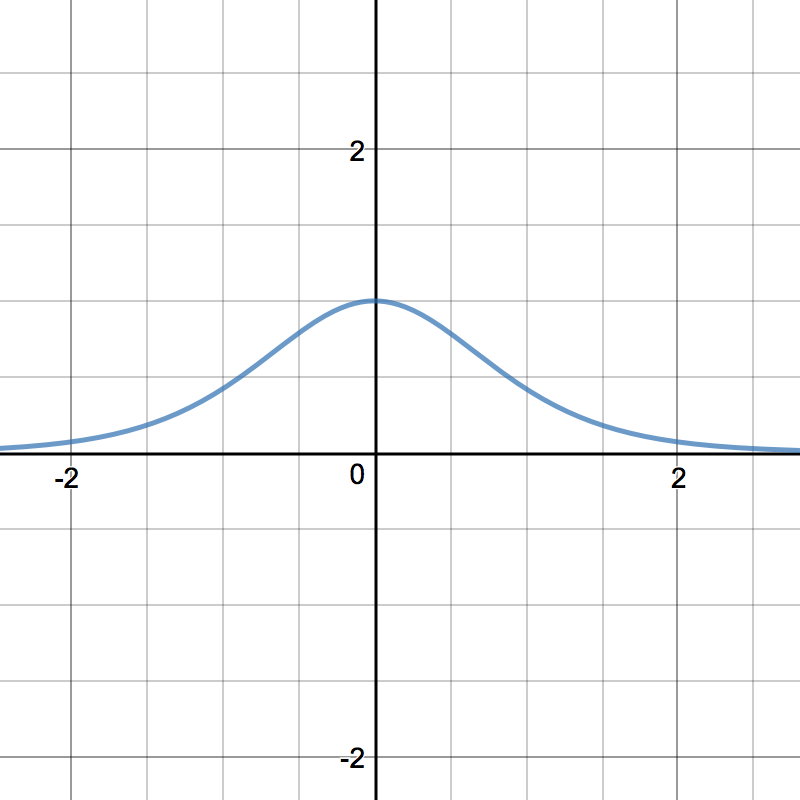
Tanh¶
Hàm Tanh nén một số có giá trị thực về khoảng \([-1, 1]\). Tanh cũng là hàm phi tuyến, nhưng khác với Sigmoid, nó có đầu ra có trung bình bằng không. Do đó, trên thực tế thì tính phi tuyến của Tanh thường được ưa chuộng hơn tính phi tuyến của Sigmoid 1.
Hàm số |
Đạo hàm |
\[tanh(z) = \frac{e^{z} - e^{-z}}{e^{z} + e^{-z}}\]
|
\[tanh'(z) = 1 - tanh(z)^{2}\]
|
|
|
def tanh(z):
return (np.exp(z) - np.exp(-z)) / (np.exp(z) + np.exp(-z))
|
def tanh_prime(z):
return 1 - np.power(tanh(z), 2)
|
Ưu điểm
Gradient của Tanh mạnh hơn Sigmoid (có đạo hàm dốc hơn).
Nhược điểm
Tanh cũng gặp phải vấn đề tiêu biến gradient.
Softmax (TODO)¶
Hàm Softmax được tính bằng phân phối xác suất của sự kiện trong n sự kiện khác nhau. Nói một cách dễ hiểu hơn, hàm này sẽ tính xác suất của mỗi danh mục trên tất cả các danh mục khả dĩ. Sau đó, xác suất tính được sẽ giúp ích trong việc xác định danh mục của các đầu vào của mô hình.
References