Thuật ngữ cơ bản¶
Định nghĩa của một số thuật ngữ cơ bản được sử dụng phổ biến trong các tài liệu học máy.
- Độ chính xác - Accuracy
Là tỉ lệ phần trăm mà mô hình đưa ra dự đoán đúng.
- Thuật toán - Algorithm
Là một phương pháp, phương thức, hay một tập hợp các lệnh được sử dụng để tạo ra một mô hình học máy.
Ví dụ có thể kể đến các thuật toán hồi quy tuyến tính, cây quyết định (decision trees), máy vector hỗ trợ (support vector machines), và các thuật toán dựa trên kiến trúc mạng nơ-ron.
- Thuộc tính - Attribute
Là một tính chất được sử dụng để mô tả một quan sát (ví dụ như màu sắc, kích cỡ, cân nặng). Trong các cơ sở dữ liệu dạng bảng tính (ví dụ như Excel, CSV, ...), các thuộc tính chính là tiêu đề của các cột.
- Độ lệch - Bias metric
Miêu tả độ sai lệch trung bình giữa dự đoán của mô hình và giá trị thực của các quan sát.
Độ lệch thấp có thể biểu thị rằng đa phần các dự đoán đều đúng. Nó cũng có thể có nghĩa là một nửa các giá trị dự đoán cao hơn giá trị thực và một nửa còn lại thấp hơn với tỉ lệ tương đương, khiến cho độ sai lệch trung bình (tức độ lệch) thấp.
Độ lệch cao (với phương sai thấp) ám chỉ rằng mô hình có thể đang bị kém khớp (underfit) và bạn đang sử dụng sai mô hình với công việc cần thực hiện.
- Hệ số điều chỉnh - Bias term
Là hệ số giúp mô hình biểu diễn trường hợp mà hàm dự đoán không đi qua gốc toạ độ. Ví dụ, nếu tất cả các đặc trưng đều mang giá trị \(0\), liệu dự đoán ở đầu ra cũng sẽ bằng \(0\)? Liệu có tồn tại một giá trị cơ sở nào đó mà các đặc trưng tác động lên thay vì giá trị \(0\)? Hệ số điều chỉnh được đưa vào để giúp mô hình nắm bắt được giá trị cơ sở đó.
Hệ số điều chỉnh thường đi kèm với trọng số trong các mô hình học máy, các nơ-ron nhân tạo hay các bộ lọc (filters).
- Biến hạng mục - Categorical Variables
Là các biến mà có giá trị thuộc một tập rời rạc các giá trị khả dĩ. Tập này có thể có thứ tự (ordinal) hoặc là một tập định danh không có thứ tự (nominal).
- Phân loại - Classification
Dự đoán danh mục của đầu ra.
Phân loại nhị phân dự đoán một trong hai kết quả khả dĩ (ví dụ như email đó là thư rác hay không?).
Phân loại đa lớp dự đoán một trong nhiều kết quả khả dĩ (ví dụ như bức ảnh đó là ảnh một con mèo, chó, ngựa, hay ảnh chụp người?).
- Ngưỡng phân loại - Classification Threshold
Là giá trị xác suất thấp nhất mà ta có thể tự tin khẳng định rằng quan sát đó là dương tính.
Ví dụ, nếu xác suất dự đoán bệnh tiểu đường \(> 50\%\), trả về kết quả dương tính (True), ngược lại trả về kết quả âm tính.
- Phân cụm - Clustering
Phân nhóm dữ liệu thành các nhóm khác nhau một cách không giám sát.
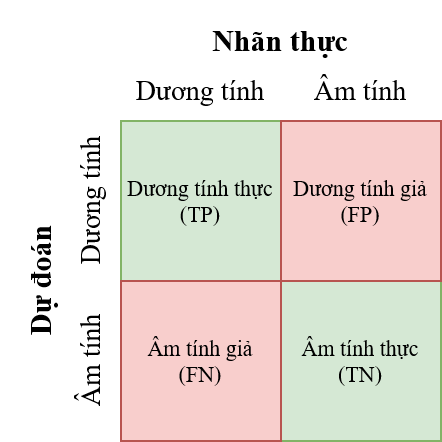
- Ma trận nhầm lẫn - Confusion Matrix
Là một bảng mô tả hiệu năng của mô hình phân loại bằng cách nhóm các dự đoán thành 4 nhóm.
Dương tính thật (*True Positives*): mô hình dự đoán đúng khi trả về kết quả dương tính.
Âm tính thật (*True Negatives*): mô hình dự đoán đúng khi trả về kết quả âm tính.
Dương tính giả (*False Positives*): mô hình dự đoán sai khi trả về kết quả dương tính (lỗi loại I).
Âm tính giả (False Negatives): mô hình dự đoán sai khi trả về kết quả âm tính. (lỗi loại II).
- Biến liên tục - Continuous Variables
Là biến có thể nhận bất cứ giá trị nào trong một khoảng giá trị liên tục (ví dụ như doanh thu, tuổi thọ).
- Hội tụ - Convergence
Là một trạng thái trong huấn luyện mô hình học máy, xảy ra khi mất mát giảm rất ít hoặc không giảm sau mỗi vòng lặp huấn luyện.
- Chi phí - Cost
Là giá trị biểu thị độ sai lệch trung bình giữa dự đoán của mô hình so với nhãn thực của quan sát trên toàn bộ tập dữ liệu. Nói cách khác, chi phí là giá trị mất mát trung bình trên toàn bộ tập dữ liệu.
Khái niệm chi phí (cost) và mất mát (loss) đôi khi có thể cùng được hiểu theo nghĩa trên.
- Suy diễn logic - Deduction
Là một phương pháp giải quyết vấn đề hay trả lời câu hỏi từ trên xuống (top-down). Đây là một kỹ thuật logic bắt đầu với một giả thuyết và kiểm tra giả thuyết đó thông qua các quan sát thực tế để dẫn tới kết luận cuối cùng.
Ví dụ, ta nghi ngờ giả thuyết X, nhưng ta cần phải kiểm chứng giả thuyết của ta trước khi đưa ra bất cứ kết luận nào.
- Học sâu - Deep Learning
Học sâu xuất phát từ một thuật toán trong học máy có tên gọi là perceptron hay perceptron đa tầng, được huấn luyện để trừu tượng hoá dữ liệu ở mức cao bằng cách xử dụng nhiều tầng xử lý phi tuyến với cấu trúc phân tầng, với mỗi tầng kế tiếp dùng kết quả đầu ra của tầng trước làm đầu vào. Học phân tầng đại diện với các mức độ trừu tượng khác nhau, các mức độ hình thành một hệ thống phân cấp của các khái niệm.
Giống như các thuật toán trí tuệ nhân tạo khác, học sâu bắt đầu được nghiên cứu vào nhiều thập kỷ trước, từ thập niên 80, nhưng với sự bùng nổ về khả năng tính toán và lượng dữ liệu ngày càng nhiều và rẻ những năm gần đây thì các thuật toán học sâu mới thực sự cho thấy tiềm năng và đạt được sự chú ý đáng có. Ngày nay, học sâu được biết đến như mạng nơ-ron nhân tạo và được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau như thị giác máy tính, xử lý tín hiệu, chẩn đoán y tế cho tới xe tự hành.
- Chiều - Dimension
Khái niệm chiều trong học máy và khoa học dữ liệu khác với khái niệm chiều không gian trong vật lý. Ở đây, Chiều của dữ liệu có nghĩa là số lượng đặc trưng có trong tập dữ liệu. Ví dụ, trong ứng dụng nhận diện vật thể, kích thước ảnh và các kênh màu RGB (ví dụ như \(28 \times 28 \times 3\)) được trải phẳng thành vector và trở thành các đặc trưng cho dữ liệu đầu vào. Ngoài ra, chẳng hạn đối với bài toán dự đoán giá nhà dựa trên diện tích nhà thì diện tích có thể được gọi là dữ liệu 1 chiều.
- Epoch
Là thuật ngữ chỉ số lần mà thuật toán duyệt qua toàn bộ tập dữ liệu (thường là tập huấn luyện).
- Ngoại suy - Extrapolation
Mô tả việc đưa ra dữ đoán cho dữ liệu ngoài phạm vi bao quát của tập dữ liệu đã học.
Ví dụ, con chó của tôi biết sủa, vì vậy tất cả các con chó khác đều biết sủa.
Trong học máy, mô hình thường vướng mắc phải nhiều vấn đề khi ta cố ngoại suy dữ liệu nằm ngoài tập huấn luyện.
- Tỉ lệ Dương tính giả - False Positive Rate (FPR)
Được định nghĩa bằng
\[FPR = 1 - S = \frac{FP}{FP + TN}\]trong đó \(FP\) và \(TN\) được định nghĩa bởi ma trận nhầm lẫn, \(S\) là độ đặc hiệu.
Tỉ lệ dương tính giả chính là trục \(x\) của đương cong ROC.
- Đặc trưng - Feature
Với mỗi tập dữ liệu, mỗi đặc trưng biểu diễn một thuộc tính đi kèm với giá trị cụ thể. "Màu sắc" là một thuộc tính của dữ liệu, và "Màu xanh dương" là một đặc trưng. Trong các cơ sở dữ liệu dạng bảng tính (ví dụ như Excel, CSV, ...), các đặc trưng tương tự như các ô mang giá trị các thuộc tính. Tuỳ vào ngữ cảnh mà thuật ngữ "đặc trưng" cũng có thể mang nghĩa khác.
- Trích chọn đặc trưng - Feature Selection
Là giai đoạn lựa chọn một tập hữu hạn các đặc trưng phù hợp từ tập dữ liệu để huấn luyện mô hình học máy. Một số lợi ích của việc áp dụng trích chọn đặc trưng có thể kể đến gồm:
Tập dữ liệu có thể chứa nhiều đặc trưng thừa thãi hay không liên quan đến mục đích huấn luyện mô hình mà có thể loại bỏ để tăng sự tương thích với mô hình dự đoán.
Giảm độ phức tạp của dữ liệu, rút ngắn thời gian huấn luyện.
Giúp việc giải thích dự đoán mô hình trở nên dễ dàng hơn với ít đặc trưng đầu vào hơn.
Các thuật toán trích chọn đặc trưng phổ biến:
(TODO)
Quá trình này còn có các tên gọi khác như trích chọn biến, trích chọn thuộc tính.
- Vector đặc trưng - Feature Vector
Là một danh sách các đặc trưng mô tả một quan sát với nhiều thuộc tính khác nhau. Trong các cơ sở dữ liệu dạng bảng tính (ví dụ như Excel, CSV, ...), mỗi hàng chính là một vector thuộc tính của một quan sát.
- Chồng chất gradient - Gradient Accumulation
Là một cơ chế chia nhỏ từng batch dữ liệu được sử dụng trong huấn luyện mạng nơ-ron thành nhiều batch nhỏ hơn (minibatch) và chạy lần lượt các batch nhỏ, sau đó tỉnh tổng (chồng chất) các gradient của từng batch nhỏ để cập nhật trọng số mô hình theo batch dữ liệu ban đầu. Cơ chế này giúp ta có thể huấn luyện mô hình với kích thước batch lớn dù bộ nhớ GPU hạn chế mà vẫn giữ được hiệu quả mong muốn.
- Siêu tham số - Hyperparameters
Là những thuộc tính mức cao của mô hình học máy mà giá trị của nó có thể điều khiển quá trình huấn luyện hay cấu trúc của mô hình, ví dụ như tốc độ học hay hệ số điều chuẩn. Độ sâu của cây trong thuật toán cây quyết định (decision tree) hay số tầng ẩn trong mạng nơ-ron cũng chính là các siêu tham số.
- Quy nạp - Induction
Là một phương pháp giải quyết vấn đề hay trả lời câu hỏi từ dưới lên (bottom-up). Đây là một kỹ thuật logic đi từ các quan sát để suy ra các luận đề.
Ví dụ, nếu ta liên tục bắt gặp quan sát X, thì ta có thể suy luận rằng Y phải đúng.
- Mẫu - Instance
Là một điểm dữ liệu, một hàng hay một mẫu trong tập dữ liệu. Thuật ngữ này đồng nghĩa với các quan sát.
- Nhãn - Label
Trong các bài toán học có giám sát, nhãn của một quan sát là giá trị mà mô hình dự đoán trả về dựa trên các đặc trưng ở đầu vào.
Ví dụ, với mô hình được huấn luyện để phân loại hoa thành các loài khác nhau, các đặc trưng đầu vào có thể bao gồm số cánh hoa, độ dài và độ rộng cánh hoá, trong khi nhãn sẽ là tên của loài hoa đó.
- Tốc độ học - Learning Rate
Là kích thước các bước cập nhật trọng số mà thuật toán tối ưu (ví dụ như gradient_descent) thực hiện trong mỗi bước lặp.
Với tốc độ học cao, ta có thể bước xa hơn với mỗi bước di chuyển, tuy nhiên nếu cao quá sẽ có nguy cơ sẽ bước lệch khỏi điểm thấp nhất do độ dốc của hàm chi phí thay đổi liên tục. Với một tốc độ học thấp, ta có thể tự tin di chuyển theo chiều âm của gradient do ta liên tục tính lại giá trị này. Tốc độ học thấp sẽ cho độ chính xác tốt hơn, tuy nhiên việc tính gradient nhiều lần rất tốn thời gian, do đó ta sẽ cần nhiều thời gian hơn để bước được tới điểm cực tiểu.
- Mất mát - Loss
Thông thường, khái niệm mất mát được sử dụng để ám chỉ lỗi dự đoán của mô hình so với nhãn thực của một quan sát trong tập dữ liệu. Tuy nhiên, khái niệm này tương đồng với chi phí và nhiều tài liệu thường sử dụng cả hai khái niệm này để chỉ chi phí dự đoán trên toàn bộ tập dữ liệu.
Mất mát càng thấp, hiệu năng của mô hình càng tốt (trừ khi mô hình bị hiện tượng quá khớp dữ liệu huấn luyện). Mất mát được tính toán trên tập huấn luyện và kiểm định với mục đích để thể hiện khả năng dự đoán của mô hình trên 2 tập dữ liệu này. Khác với độ chính xác, mất mát không phải là tỷ lệ phần trăm, mà là lỗi dự đoán trên từng mẫu của tập huấn luyện và tập kiểm tra.
- Học máy - Machine Learning
Mitchell (1997) đưa ra định nghĩa ngắn gọn về học máy như sau: "Một chương trình máy tính được coi là học từ kinh nghiệm E để thực hiện một nhóm các tác vụ T và hiệu năng được đo bằng P, nếu hiệu năng của nó đo bởi P khi thực hiện các tác vụ T được cải thiện với kinh nghiệm E".
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E." - Mitchell (1997)Nói một cách đơn giản hơn, học máy là một lĩnh vực mà con người thực thi các thuật toán có khả năng tự học và dự đoán tương lai khả dĩ cho dữ liệu chưa biết.
- Mô hình - Model
Là một cấu trúc dữ liệu lưu trữ dạng biểu diễn mô hình hoá của một tập dữ liệu (dưới dạng trọng số và hệ số điều chỉnh). Các mô hình được tạo ra/học khi ta thực hiện huấn luyện một thuật toán trên một tập dữ liệu nào đó.
- Mạng nơ-ron - Neural Networks
Là các thuật toán toán học lấy cảm hứng từ cách hoạt động của bộ não con người, được thiết kế để nhận dạng mẫu và các mối quan hệ trong dữ liệu.
- Chuẩn hoá - Normalization
Trong học máy, chuẩn hoá là một bước trong khâu chuẩn bị dữ liệu với mục đích biến đổi các đặc trưng mang giá trị số về cùng một khoảng giá trị chung mà vẫn giữ nguyên dạng phân phối chung và tỉ lệ của dữ liệu gốc, không làm hao tổn thông tin trong một thuộc tính.
Đây là một bước bắt buộc trong nhiều thuật toán học máy, hỗ trợ việc kết hợp các đặc trưng có tỉ lệ chênh lệch lớn để đưa ra dự đoán chính xác.
- Nhiễu - Noise
Là bất cứ thông tin không liên quan hay ngẫu nhiên trong tập dữ liệu gây ảnh hướng đến mẫu (pattern) dữ liệu.
- Độ chính xác gốc - Null Accuracy
Là độ chính xác cơ sở thu được khi mô hình luôn đưa ra dự đoán là danh mục có tần suất cao nhất ("Danh mục B có tần suất xuất hiện cao nhất trong tập dữ liệu, vì vậy đối với mọi quan sát khác mô hình luôn dự đoán là B").
- Quan sát - Observation
Là một điểm dữ liệu, một hàng, hay một mẫu trong tập dữ liệu. Thuật ngữ này đồng nghĩa với mẫu dữ liệu.
- Dữ liệu ngoại lai - Outlier
Là một quan sát có chênh lệch đáng kể so với các quan sát còn lại trong tập dữ liệu.
Ví dụ, trong bài toán dự đoán nhà dựa trên diện tích sàn, hầu hết các căn nhà đều có giá trung bình 20 triệu VND / m2, tuy nhiên lại có 1 căn nhà vì nhiều lý do có giá lên tới 50 triệu VND / m2, ta gọi dữ liệu căn nhà đó là dữ liệu ngoại lai.
- Quá khớp - Overfitting
Là hiện tượng xảy ra khi mô hình học dữ liệu huấn luyện quá sâu đến mức mô hình hoá cả các chi tiết thừa thãi và nhiễu trong tập huấn luyện.
Thông thường, ta có thể nhận ra mô hình bị quá khớp khi hiệu năng của nó rất tốt trên tập huấn luyện, nhưng lại kém hơn nhiều khi thực hiện dự đoán trên tập kiểm định / kiểm tra (hoặc dữ liệu mới).
- Tham số - Parameters
Là những giá trị của mô hình mà được học trong quá trình huấn luyện một mô hình học máy trên dữ liệu huấn luyện. Các tham số được cập nhật và điều chỉnh thông qua các thuật toán tối ưu khác nhau tuỳ vào loại mô hình và bài toán cần giải quyết.
Một số ví dụ về tham số bao gồm:
các trọng số trong mạng nơ-ron nhân tạo.
các vector hỗ trợ trong máy vector hỗ trợ (SVM).
các hệ số trong hồi quy tuyến tính hay logistic.
- Độ chuẩn xác - Precision
Khác với độ chính xác, trong ngữ cảnh bài toán phân loại nhị phân (Có/Không), độ chuẩn xác đo hiệu năng phân loại các quan sát dương tỉnh của mô hình (ngược lại so với độ đặc hiệu). Nói cách khác, khi quan sát đó là dương tính trong thực tế, thì tỉ lệ dự đoán đúng là bao nhiêu?
Độ chuẩn xác \(P\) được tính theo công thức
\[P = \frac{TP}{TP + FP}\]trong đó \(TP\) and \(FP\) được định nghĩa bởi ma trận nhầm lẫn.
Một mánh khoé để đạt độ đặc hiệu tối đa là đưa ra dự đoán dương tính cho tất cả các quan sát.
- Độ nhạy - Recall
Trong ngữ cảnh bài toán phân loại nhị phân (Có/Không), độ nhạy đo "sự nhạy bén" của mô hình phân loại trong việc phát hiện ra các quan sát dương tính. Nói cách khác, trên tổng số tất cả các quan sát dương tính trong tập dữ liệu, mô hình phân loại đúng được bao nhiêu quan sát là dương tính.
Độ nhạy \(R\) được tính theo công thức
\[R = \frac{TP}{TP + FN}\]trong đó \(TP\) and \(FN\) được định nghĩa bởi ma trận nhầm lẫn.
Một mánh khoé để đạt độ đặc hiệu tối đa là đưa ra dự đoán dương tính cho tất cả các quan sát.
- Độ nhạy so với Độ chuẩn xác
Giả sử ta đang phân tích các bản chụp não và cần phải đưa ra dự đoán rằng người khám có khối u trong não hay không. Ta đưa các bản chụp vào mô hình và bắt đầu dự đoán.
Độ chuẩn xác là % các dự đoán dương tính (có khối u) là chính xác. Nếu ta dự đoán có 1 ảnh chụp trong số 100 ảnh có khối u và người bệnh đó đúng là có khối u trong não, vậy thì độ chuẩn xác của dự đoán là 100%. Tuy nhiên kết quả này không được hữu ích cho lắm do là ta đã bỏ qua 9 khối u não của 9 bệnh nhân khác. Dù độ chuẩn xác là rất cao, nhưng ta cần phải tìm cách khác cho bài toán này.
Độ nhạy đưa ra một cái nhìn khác về khả năng dự đoán của mô hình. Quay trở lại ví dụ trên với 100 ảnh chụp não, trong đó có 10 ảnh là có khối u, và ta dự đoán đúng 1 ảnh là có khối u. Độ chuẩn xác là 100%, nhưng độ nhạy chỉ là 10%. Để đạt được độ nhạy hoàn hảo, ta cần phải đoán được cả 10 khổi u.
Ở ví dụ trên, trường hợp ta đoán có 20 ảnh là dương tính, nhưng trong đó có bao gồm cả 10 ảnh đúng là có khổi u và 10 ảnh không có, thì vẫn đạt độ nhạy 100%, và độ chuẩn xác sẽ thấp hơn. Tuy nhiên ta cần phải ưu tiên độ nhạy do đối với 10 bệnh nhân không có khối u bị chẩn đoán sai, họ có thể lo lắng và phải khám lại nhưng sẽ không ảnh hưởng lâu dài, còn đối với 9 bệnh nhân có khối u mà không được chẩn đoán kịp thời rất có thể sẽ nguy hiểm đến tính mạng.
Tóm lại, Độ nhạy và Độ chuẩn xác đều là những phép đo mô tả khả năng dự đoán của mô hình. Tuy nhiên, tuỳ thuộc vào bài toán cụ thể mà ta cần cân nhắc ưu tiên sử dụng phép đo nào hơn so với cái còn lại.
- Hồi quy - Regression
Là một dạng mô hình phân tích mối quan hệ phụ thuộc của nhãn có giá trị liên tục (ví dụ như giá cả, doanh thu) vào các đặc trưng của dữ liệu để đưa ra dự đoán cho các dữ liệu mới.
- Điều chuẩn - Regularization
Là một kỹ thuật được sử dụng để tránh hiện tượng quá khớp trong huấn luyện mô hình học máy. Kỹ thuật này cộng vào hàm mất mát một hệ số phức tạp (complexity term) khiến cho mô hình càng phức tạp thì mất mát dự đoán càng lớn.
Trong mạng nơ-ron nhân tạo hiện đại, các phương pháp điều chuẩn phổ biến được mô tả kỹ hơn trong regularization_vn.
- Học tăng cường - Reinforcement Learning
Là phương pháp huấn luyện mô hình để tối đa phần thưởng nhận được qua mỗi lần thử và lỗi.
- Đương cong đặc trưng hoạt động của bộ thu - Receiver Operating Characteristic (ROC) Curve
Là một đồ thị biểu diễu tỉ lệ dương tính đúng, hay độ nhạy, trên tỉ lệ dương tính giả với mọi ngưỡng phân loại. Đồ thị này được sử dụng để đánh giá hiệu năng phân loại của mô hình với các ngưỡng phân loại khác nhau.
Phần diện tích phía dưới đường cong ROC có thể được coi là xác suất mà mô hình phân biệt đúng một quan sát ngẫu nhiên dương tính (như "có u não") và một quan sát ngẫu nhiên âm tính (như "không có u não").
- Phân vùng - Segmentation
là quá trình tách tập dữ liệu thành nhiều tập riêng biệt. Việc tách tập dữ liệu này được thực hiện sao cho các phần tử trong cùng 1 tập là tương đồng nhau và khác với các phần tử dữ liệu của các tập còn lại.
- Độ đặc hiệu - Specificity
Trong ngữ cảnh bài toán phân loại nhị phân (Có/Không), độ đặc hiệu đo hiệu năng phân loại các quan sát âm tỉnh của mô hình (ngược lại so với độ chuẩn xác). Nói cách khác, khi quan sát đó là âm tính trong thực tế, thì tỉ lệ dự đoán đúng là bao nhiêu?
Độ đặc hiệu \(S\) được tính theo công thức
\[S = \frac{TN}{TN + FP}\]trong đó \(TN\) and \(FP\) được định nghĩa bởi ma trận nhầm lẫn.
Một mánh khoé để đạt độ đặc hiệu tối đa là đưa ra dự đoán âm tính cho tất cả các quan sát.
- Học có giám sát - Supervised Learning
Là phương pháp huấn luyện mô hình học máy sử dụng dữ liệu đã được gắn nhãn. Các nhãn này sẽ được sử dụng để so sánh với đầu ra của mô hình và từ đó điều chỉnh các tham số mô hình cho phù hợp.
- Tập kiểm tra - Test Set
Là một tập các quan sát được sử dụng sau khi đã hoàn thành quá trình huấn luyên và kiểm định để đánh giá khả năng dự đoán của mô hình học máy. Việc sử dụng tập kiểm tra giúp đánh giá mức độ tổng quát của mô hình đối với dữ liệu chưa biết.
- Tập huấn luyện - Training Set
Là một tập các quan sát được sử dụng để tạo thành mô hình học máy thông qua quá trình huấn luyện.
- Học truyền tải - Transfer Learning
Là một phương pháp học máy mà trong đó một mô hình đã được phát triển cho một tác vụ cụ thể được tái sử dụng để làm điểm khởi đầu cho một mô hình khác với tác vụ khác. Trong phương pháp học truyền tải, ta lấy trọng số tiền huấn luyện (pre-trained) của một mô hình đã được huấn luyện trước (ví dụ như một mô hình tiền huấn luyện bởi nhiều GPU qua nhiều ngày trên 1 triệu ảnh thuộc 1000 danh mục) và sử dụng các đặc trưng đã được học đó để dự đoán cho các danh mục mới.
- Tỉ lê dương tính thật - True Positive Rate
Là một cách gọi khác của độ nhạy.
Tỉ lệ dương tính thật chính là trục y của đồ thị đường cong ROC.
- Lỗi loại 1 - Type 1 Error
Tức là các trường hợp dự đoán dương tính giả.
Giả sử một công ty cần tối ưu quy trình tuyển dụng. Lỗi loại 1 xảy ra khi ứng viên đó thoạt nhìn thì có vẻ phù hợp và công ty quyết định mời vào làm việc, nhưng thực chất anh ta lại không làm được việc.
- Lỗi loại 2 - Type 2 Error
Tức là các trường hợp dự đoán âm tính giả.
Giả sử một công ty cần tối ưu quy trình tuyển dụng. Lỗi loại 2 xảy ra khi ứng viên rất tốt và phù hợp với công ty nhưng lại bị loại trong quá trình tuyển dụng.
- Kém khớp - Underfitting
Là hiện tượng xảy ra khi mô hình học máy khái quát hoá quá mức và không thể học được những biễn thiên thích đáng trong dữ liệu mà có thể giúp mô hình có khả năng dự đoán tốt hơn. Ta có thể nhận thấy một mô hình dự đoán bị kém khớp khi hiệu năng của mô hình kém trên cả tập huấn luyện và tập kiểm tra.
- Định lý xấp xỉ phổ quát - Universal Approximation Theorem
Nói một cách đơn giản, định lý này phát biểu rằng một mạng nơ-ron với chỉ 1 tầng ẩn có thể xấp xỉ bất cứ hàm liên tục nào nhưng chỉ với đầu vào trong 1 khoảng giá trị nhất định.
Ví dụ, nếu ta huấn luyện một mô hình với đầu vào trong khoảng từ -2 đến 2, mô hình sẽ hoạt động tốt với đầu vào trong cùng khoảng giá trị đó, nhưng ta không thể mong rằng mô hình có thể khái quát hoá với các đầu vào có khoảng giá trị khác mà không huấn luyện lại mô hình, hoặc thêm nơ-ron ẩn vào mạng.
- Học không giám sát - Unsupervised Learning
Là phương pháp huấn luyện mô hình để mô hình hoá cấu trúc, phân bố giá trị, hay thông tin ẩn trong dữ liệu. Học không giám sát thường được ứng dụng để mô tả tính chất hay cấu trúc của dữ liệu, từ đó áp dụng vào các bài toán cụ thể như phân cụm dữ liệu hay giảm chiều dữ liệu.
- Tập kiểm định - Validation Set
Là một tập các quan sát được sử dụng trong giai đoạn huấn luyện mô hình (song song và tách biệt khỏi tập huấn luyện) để cung cấp phản hồi về khả năng khái quát quá dữ liệu ngoài tập huấn luyện của các tham số mô hình hiện tại, từ đó cho phép ta có thể điều chỉnh quá trình học sao cho phù hợp. Nếu trong quá trình huấn luyện, lỗi huấn luyện giảm nhưng lỗi kiểm định lại tăng thì khả năng cao là mô hình đã bị quá khớp và ta nên dừng quá trình huấn luyện lại.
- Phương sai - Variance
Là thông số mô tả độ phân tán của các dự đoán của mô hình khi có 1 sự thay đổi rất nhỏ trong tập huấn luyện.
Phương sai thấp ám chỉ rằng mô hình đưa ra dự đoán khá ổn định, với các dự đoán chỉ dao động trong một khoảng nhỏ.
Phương sai cao (với độ lệch thấp) ám chỉ rằng mô hình có thể đang bị quá khớp và mô hình hoá dữ liệu quá sâu đến cả nhiễu trong tập huấn luyện.
Tài liệu tham khảo