Hàm Mất mát - Loss Functions¶
Entropy chéo - Cross-Entropy¶
Mất mát entropy chéo, hay mất mát log, đo hiệu năng của mô hình phân loại đưa ra kết quả dự đoán là giá trị xác xuất từ \(0\) đến \(1\). Mất mát entropy chéo tăng khi giá trị xác xuất dự đoán bị lệch xa khỏi nhãn thực tế. Tức là nếu mô hình dự đoán xác suất \(0.012\) trong khi nhãn của quan sát đó trong thực tế là \(1\) (tức là dự đoán sai hoàn toàn) thì giá trị mất mát sẽ rất cao.
Một mô hình phân loại hoàn hảo sẽ có mất mát log bằng \(0\).
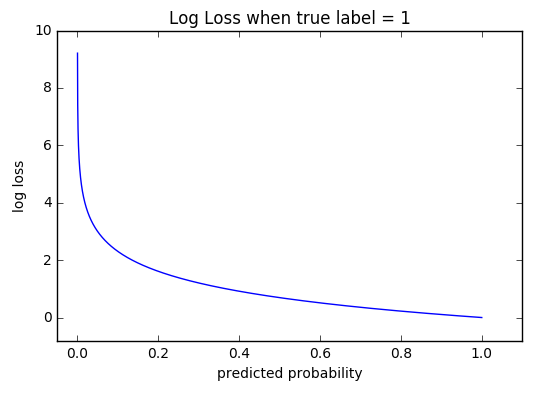
Đồ thị trên mô tả khoảng giá trị của hàm mất mát entropy chéo theo một quan sát dương tính (isDog = 1).
Với giá trị xác suất dự đoán tiến tới \(1\), mất mát log giảm rất chậm và tiến tới \(0\).
Tuy nhiên, khi xác suất dự đoán giảm dần, mất mát log tăng theo cấp số nhân và tiến tới vô cùng.
Điều này có nghĩa là dù mất mát log phạt tất cả giá trị dự đoán khác giá trị nhãn thực, những dự đoán sai với độ tin cậy cao sẽ bị phạt rất nặng.
Mất mát entropy chéo và mất mát log có 1 chút khác biệt tuỳ thuộc vào cách dùng, nhưng trong học máy khi giá trị đầu ra trong khoảng từ \(0\) đến \(1\), chúng có ý nghĩa tương đương nhau.
Code
def CrossEntropy(yHat, y):
if y == 1:
return -log(yHat)
else:
return -log(1 - yHat)
Công thức toán học
Trong bài toán phân loại nhị phân, khi số danh mục \(M = 2\), entropy chéo có thể được tính bằng:
Nếu \(M > 2\) (tức là bài toán phân loại đa lớp), ta tính mất mát cho từng danh mục theo mỗi quan sát và sau đó tính tổng mất mát.
trong đó:
\(M\) là số danh mục.
\(\log\) là hàm logarit tự nhiên.
\(y\) là chỉ mục (mang giá trị \(1\) hoặc \(0\)) thể hiện việc phân loại quan sát \(o\) vào danh mục \(c\) là đúng hay sai.
\(p\) là xác suất dự đoán quan sát \(o\) thuộc danh mục \(c\).
Mất mát Hinge¶
Là mất mát được sử dụng trong bài toán phân loại.
Code
def Hinge(yHat, y):
return np.max(0, y - (1-2*y)*yHat)
Mất mát Huber¶
Mất mát Huber thường được sử dụng trong bài toán hồi quy. Loại mất mát này ít bị ảnh hưởng bởi các điểm dữ liệu ngoại lai hơn so với MSE do nó chỉ tính bình phương lỗi trong một khoảng nhất định (\([-\delta, \delta]\)), ngoài khoảng đó lỗi được tính theo hàm tuyến tính.
Công thức toán học
Code
def Huber(yHat, y, delta=1.):
return np.where(np.abs(y-yHat) < delta,.5*(y-yHat)**2 , delta*(np.abs(y-yHat)-0.5*delta))
Bạn đọc có thể tham khảo `Trang Wikipedia về Mất mát Huber`_.
Mất mát Kullback-Leibler¶
Code
def KLDivergence(yHat, y):
"""
:param yHat:
:param y:
:return: KLDiv(yHat || y)
"""
return np.sum(yHat * np.log((yHat / y)))
MAE (L1)¶
Trung bình Sai số Tuyệt đối (Mean Absolute Error - MAE), hay mất mát L1. Bạn đọc có thể tham khảo thêm chi tiết trong bài viết 9 và 10.
Code
def L1(yHat, y):
return np.sum(np.absolute(yHat - y)) / y.size
MSE (L2)¶
Trung bình Bình phương Sai số (Mean Squared Error - MSE), hay mất mát L2. Bạn đọc có thể tham khảo thêm chi tiết trong bài viết 9 và 10.
def MSE(yHat, y):
return np.sum((yHat - y)**2) / y.size
def MSE_prime(yHat, y):
return yHat - y
Tài liệu tham khảo
- 1
- 2
- 3
https://en.wikipedia.org/wiki/Loss_functions_for_classification
- 4
http://www.exegetic.biz/blog/2015/12/making-sense-logarithmic-loss/
- 5
- 6
https://en.wikipedia.org/wiki/S%C3%B8rensen%E2%80%93Dice_coefficient
- 7
- 8
- 9(1,2)
- 10(1,2)
http://www.chioka.in/differences-between-l1-and-l2-as-loss-function-and-regularization/