Bộ Tối ưu - Optimizer¶
Bộ tối ưu là gì?
Trong giai đoạn huấn luyện, tác vụ quan trọng nhất là cập nhật các tham số của mô hình sao cho dự đoán của mô hình càng chính xác và càng tối ưu càng tốt. Nhưng chính xác thì việc cập nhật tham số được thực hiện thế nào? Những tham số nào của mô hình cần cập nhật, khi nào thì cập nhật và cập nhật 1 lượng bằng bao nhiêu?
Câu trả lời tốt nhất cho các câu hỏi trên là các bộ tối ưu. Bộ tối ưu liên kết hàm mất mát với các tham số mô hình bằng cách cập nhật mô hình dựa theo giá trị trả về của hàm mất mát. Nói đơn giản hơn, bộ tối ưu giúp định hình mô hình thành dạng chính xác nhất có thể thông qua việc điều chỉnh trọng số. Hàm mất mát có thể được coi là bộ phận dẫn đường cho bộ tối ưu cho biết nên di chuyển theo hướng nào.
Phần này sẽ liệt kê một số bộ tối ưu trong học máy.
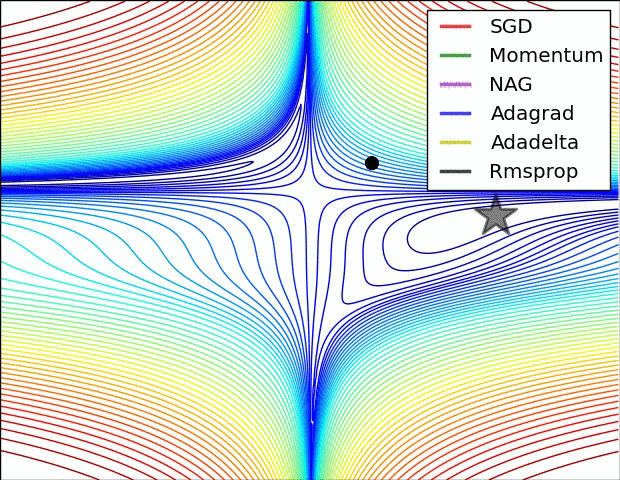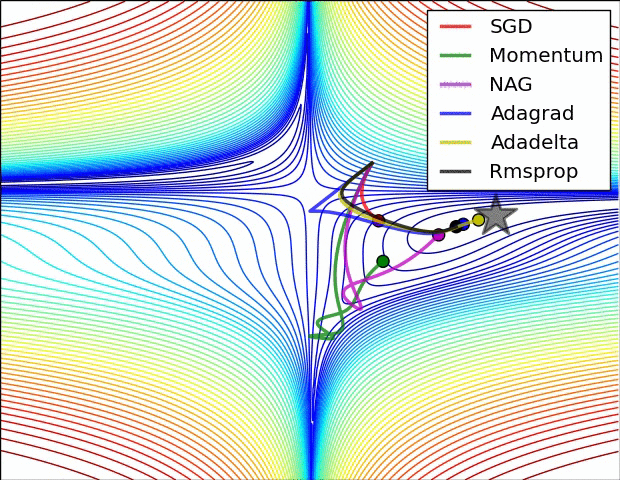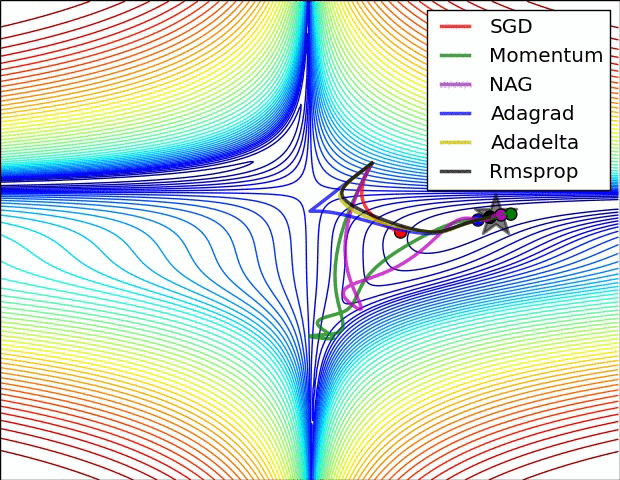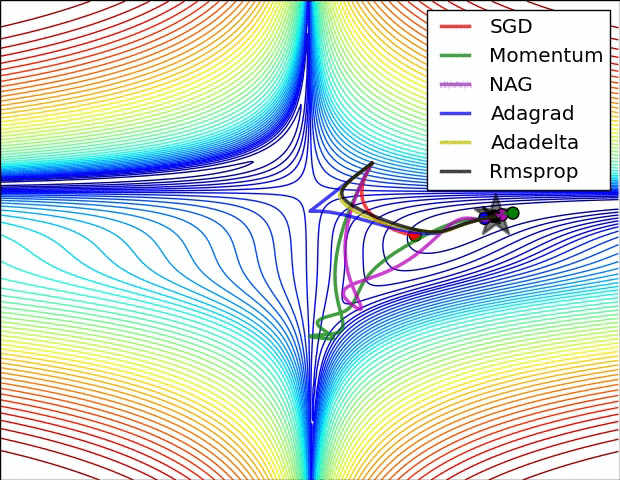
Adagrad¶
Adagrad (viết tắt của gradient thích ứng - Adaptive Gradient) tự động thay đổi tốc độ học của 1 tham số để thích nghi với giá trị gradient của tham số đó.
Các tham số có gradient cao hoặc được cập nhật thường xuyên nên có tốc độ học chậm hơn để tránh trường hợp mô hình không cập nhật lệch khỏi giá trị tối ưu nhất.
Các tham số có graident thấp hoặc ít được cập nhật nên có tốc độ học nhanh hơn để quá trình huấn luyện diễn ra nhanh hơn.
Adagrad thích nghi tốc độ học bằng cách chia tốc độ học cho tổng bình phương của tất cả các gradient trước đó theo từng tham số. Khi tổng bình phương đó có giá trị cao, tốc độ học sẽ được chia cho số lớn hơn 1 để giảm tốc độ học đi. Tương tự, khi tổng bình phương đó có giá trị thấp, tốc độ học sẽ được chia cho số nhỏ hơn 1 để tăng tốc độ học lên.
Về mặt toán học, tốc độ học tỉ lệ nghịch với tổng bình phương của tất cả gradient tại các bước trước theo tham số đó.
trong đó:
\(g_{t}^{i}\) - gradient theo một tham số, \(\Theta\) tại vòng lặp \(t\).
\(\alpha\) - tốc độ học.
\(\epsilon\) - một giá trị rất nhỏ để tránh lỗi chia cho \(0\).
Adadelta¶
AdaDelta là một phiên bản mở rộng của Adagrad, thuộc họ các thuật toán hạ gradient ngẫu nhiên (stochastic gradient descent), cung cấp giải pháp tinh chỉnh tập siêu tham số. AdaDelta viết tắt cho delta thích ứng (adaptive delta), trong đó delta ý chỉ sự chênh lệch giữa trọng số hiện tại và trọng số mới được cập nhật.
Nhược điểm chính của Adagrad là nó cần tính tổng bình phương tất cả gradient. Trong quá trình huấn luyện, tổng này tăng liên tục, và từ công thức của Adagrad ta có thể thấy rằng việc tăng tổng bình phương gradient sẽ dần khiến cho tốc độ học giảm đến quá nhỏ, và đến một lúc nào đó quá trình huấn luyện sẽ bị ngưng lại và không thể học thêm được kiến thức gì từ dữ liệu nữa.
Khác với Adagrad, AdaDelta mạnh mẽ hơn ở chỗ nó thích nghi tốc độ học dựa theo một cửa sổ chứa một số cập nhật gradient nhất định, thay vì toàn bộ các gradient tại các bước cập nhật trước. Bằng cách này, AdaDelta có thể liên tục học và cập nhật ngay cả khi đã qua rất nhiều bước cập nhật trọng số.
Với AdaDelta, ta không cần phải xác định giá trị tốc độ học mặc định do tốc độ học không còn cần thiết trong công thức cập nhật nữa.
Công thức toán học có dạng như sau:
Adam¶
Adam, viết tắt cho Ước lượng Mô-men Thích ứng (Adaptive Moment Estimation), là ý tưởng kết hợp giữa RMSProp và Tối ưu theo động lượng. Bộ tối ưu này thích ứng tốc độ học cho từng tham số theo các bước sau:
Tính trung bình trọng số mũ của các gradient trước đó (\(v_{dW}\)).
Tính trung bình trọng số mũ của bình phương các gradient trước đó (\(s_{dW}\)).
Các giá trị trung bình trên có xu hướng tiến tới \(0\) và do đó một bước điều chỉnh độ lệch được áp dụng (\(v_{dW}^{corrected}\), \(s_{dW}^{corrected}\)).
Cập nhật tham số mô hình sử dụng các trung bình tính được ở trên.
trong đó:
\(v_{dW}\) - trung bình trọng số mũ của các gradient trước đó.
\(s_{dW}\) - trung bình trọng số mũ của bình phương các gradient trước đó.
\(\beta_1\) - siêu tham số cần tinh chỉnh.
\(\beta_2\) - siêu tham số cần tinh chỉnh.
\(\frac{\partial \mathcal{J} }{ \partial W }\) - gradient chi phí theo tầng hiện tại.
\(W\) - ma trận trọng số (các tham số cần cập nhật).
\(\alpha\) - tốc độ học.
\(\epsilon\) - một giá trị rất nhỏ để tránh lỗi chia cho \(0\).
Gradient Liên hợp - Conjugate Gradients¶
Be the first to contribute!
BFGS¶
Be the first to contribute!
Tối ưu theo Động lượng - Momentum¶
Bộ tối ưu Mô-men sử dụng gradient tại các bước cập nhật trước để làm mượt quá trình cập nhật tham số trong Hạ gradient ngẫu nhiên hoặc Hạ gradient theo batch nhỏ. Động lượng được thể hiện qua biến \(v\) ký hiệu trung bình trọng số mũ của gradient tại các bước cập nhật trước. Việc này giúp giảm sự dao động của hàm lỗi và tăng tốc độ hội tụ của quá trình huấn luyện.
trong đó:
\(v\) - trung bình trọng số mũ của gradient tại các bước cập nhật trước.
\(\frac{\partial \mathcal{J} }{ \partial W }\) - gradient chi phí theo trọng số tại tầng hiện tại.
\(W\) - ma trận trọng số.
\(\beta\) - siêu tham số cần tinh chỉnh.
\(\alpha\) - tốc độ học.
Nesterov Momentum¶
Be the first to contribute!
Newton's Method¶
Be the first to contribute!
RMSProp¶
RMSProp, viêt tắt cho Lan truyền theo Căn bậc hai Trung bình Bình phương (Root Mean Square Propagation), là một thuật toán tối ưu thích ứng tốc độ học khác hoạt động bằng cách tính giá trị trung bình trọng số mũ của gradient tại các bước cập nhật trước. RMSProp sau đó chi tốc độ học cho giá trị trung bình này để tăng tốc độ hội tụ.
trong đó:
\(s\) - trung bình trọng số mũ của bình phương các gradient trước đó.
\(\frac{\partial \mathcal{J} }{\partial W }\) - gradient chi phí theo trọng số tại tầng hiện tại.
\(W\) - ma trận trọng số.
\(\beta\) - siêu tham số cần tinh chỉnh.
\(\alpha\) - tốc độ học.
\(\epsilon\) - một giá trị rất nhỏ để tránh lỗi chia cho \(0\).
Hạ Gradient Ngẫu nhiên - Stochastic Gradient Descent¶
Trong SGD, viết tắt cho Hạ Gradient Ngẫu nhiên (Stochastic Gradient Descent), tại mỗi bước cập nhật, chỉ 1 vài mẫu dữ liệu được lựa chọn ngẫu nhiên được sử dụng để huấn luyện thay vì toàn bộ tập dữ liệu. Tuy việc sử dụng cả tập dữ liệu để tính gradient rất hữu dụng trong việc tìm điểm giá trị mất mát nhỏ nhất một cách ít nhiễu và ít ngẫu nhiên, nhưng sẽ là một vấn đề khó nếu tập dữ liệu của ta rất lớn.
Vấn đề này được giải quyết bằng hạ gradient ngẫu nhiên. SGD chỉ sử dụng 1 mẫu dữ liệu được chọn ngẫu nhiên để tính gradient.
Do chỉ sử dụng 1 điểm dữ liệu trong tập dữ liệu được chọn ngẫu nhiên tại mỗi bước tính toán, quá trình mà thuật toán tìm giá trị nhỏ nhất thường nhiễu hơn nhiều so với thuật toán hạ gradient thông thường. Nhưng con đường đi tới giá trị nhỏ nhất đó không quan trọng, miễn là ta tìm được điểm nhỏ nhất đó với khoảng thời gian huấn luyện nhanh hơn.
Trong Hạ Gradient, có một phương pháp khác có tên gọi Hạ Gradient theo Batch. Thuật ngữ gọi là "batch" ở đây ý chỉ số mẫu dữ liệu trong tập dữ liệu được sử dụng để tính gradient tại mỗi bước cập nhật thay vì chỉ 1 mẫu dữ liệu hay cả tập dữ liệu.
Tài liệu tham khảo