Lan truyền ngược - Backpropagation¶
Mục đích của quá trình lan truyền ngược khá hiển nhiên: điều chỉnh hay cập nhật trọng số của mạng tuỳ vào ảnh hưởng của nó tới tổng lỗi dự đoán của mạng. Nếu ta có thể liên tục làm giảm lỗi dự đoán của từng trọng số, cuồi cùng ta sẽ thu được một tập trọng số mà có thể đưa ra dự đoán đủ tốt.
Nhắc lại về Quy tắc chuỗi - Chain rule¶
Như đã đề cập trong Lan truyền xuôi - Forwardpropagation, quá trình lan truyền xuôi có thể được coi là một chuỗi các hàm số lồng nhau. Theo cách hiểu này, lan truyền ngược (backpropagation) gần như là một phương pháp ứng dụng Quy tắc chuỗi - Chain rule để tìm Đạo hàm - Derivatives của hàm chi phí theo bất cứ biến số (hay các trọng số) nào trong các hàm số lồng nhau đó. Cho hàm lan truyền xuôi có dạng:
A, B, và C là các hàm kích hoạt tại các tầng khác nhau trong mạng. Sử dụng quy tắc chuỗi, ta có thể dễ dàng tính được đạo hàm của \(f(x)\) theo \(x\):
Vậy còn đạo hàm theo hàm \(B\) thì sao? Để tính đạo hàm này, ta có thể coi \(B(C(x))\) là hằng số, thay bằng biến tạm thời \(B\), và tính đạo hàm của \(f(x)\) theo biến \(B\).
Phương pháp đơn giản này giúp mở rộng quy tắc chuỗi để ta có thể tính được đạo hàm theo bất cứ biến nào trong hàm hợp, cho phép ta xác định chính xác ảnh hưởng của từng biến lên đầu ra dự đoán của mạng.
Áp dụng quy tắc chuỗi¶
Hãy cùng sử dụng quy tắc chuỗi để tính đạo hàm của hàm chi phí theo bất kỳ trọng số nào trong mạng. Quy tắc chuỗi giúp ta xác định ảnh hưởng của từng trọng số lên lỗi dự đoán và hướng cập nhật cho từng trọng số để giảm lỗi. Các phương trình sau là các phương trình được sử dụng trong quá trình dự đoán và xác định lỗi dự đoán của mạng.
Hàm số |
Công thức |
Đạo hàm |
|---|---|---|
Đánh trọng số đầu vào |
\(Z = XW\) |
\(\begin{align} Z'(X) & = W \\Z'(W) & = X\end{align}\) |
Kích hoạt ReLU |
\(R = \max(0, Z)\) |
\(R'(Z) = \begin{cases} 0 \text{ khi } Z<0 \\ 1 \text{ khi } Z>0 \\ \end{cases}\) |
Hàm chi phí |
\(C = \frac{1}{2} (\hat{y} - y)^2\) |
\(C'(\hat{y}) = \hat{y} - y\) |
Cho một mạng chỉ có 1 nơ-ron duy nhất, tổng chi phí của mạng có thể được tính bằng:
Sử dụng quy tắc chuỗi, ta có thể dễ dàng tính đạo hàm của chi phí theo trọng số \(W\) bằng:
Giờ quay lại với trường hợp mạng nơ-ron đơn giản 1 tầng ẩn.
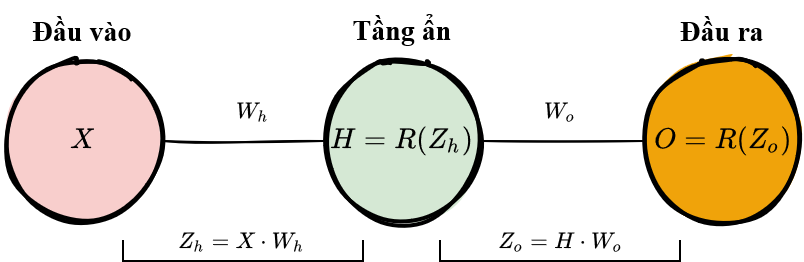
Đạo hàm của hàm chi phí theo \(W_o\) bằng
Còn đạo hàm theo \(W_h\) thì sao? Để tính đạo hàm này, ta tiếp tục áp dụng quy tắc chuỗi cho tới khi ta thu được đạo hàm theo biến \(Wh\).
Hãy thử 1 ví dụ khá thú vị với mạng nơ-ron 10 tầng ẩn. Đạo hàm của hàm chi phí với trọng số đầu tiên \(w_1\) sẽ có dạng thế nào?
Số lượng phép tính cần thực hiện để tính đạo hàm tăng lên theo chiều sâu của mạng. Tuy nhiên chú ý rằng phép tính này bị dư thừa rất nhiều. Đạo hàm hàm chi phí tại mỗi tầng thì sẽ có thêm 2 số hạng so với biểu thức tính đạo hàm mà đã được tính bởi tầng trước nó. Vậy thì liệu có cách nào có thể lưu lại giá trị tính bởi tầng trước để tránh bị lặp lại khi thực hiện đạo hàm cho tầng đằng sau không?
Để tăng tốc độ tính toán các đạo hàm theo phương pháp lan truyền ngược, ta có thể lưu các giá trị đạo hàm đã tính ở tầng trước để tránh việc tính lại hàm đó khi tính đạo hàm cho tầng sau. Chú ý rằng các công thức tính đạo hàm cho từng tầng có dạng như sau.
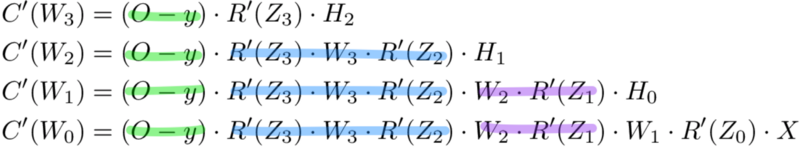
Mỗi tầng này đều có chung các thành phần đạo hàm. Do vậy, thay vì viết dạng đầy đủ công thức tính đạo hàm cho từng trọng số, ta có thể lưu lại kết quả của biểu thức đạo hàm của tầng trước đó trong quá trình "lan truyền ngược" theo kiến trúc mạng.
Trước tiên, ta tính lỗi tầng của tầng đầu ra và truyền kết quả vê tầng ẩn trước đó để sử dụng cho việc tính lỗi tầng của tầng ẩn. Sau khi tính lỗi tầng của tầng ẩn, ta truyền giá trị lỗi này về tầng ẩn trước đó, và cứ tiếp tục cho đến hết tất cả các tầng của mạng. Trong quá trính lan truyền ngược theo kiến trúc mạng, ta áp dụng công thức đạo hàm hàm chi phí để tính đạo hàm theo các trọng số của tầng đó. Các đạo hàm thu được sẽ giúp chỉ ra hướng mà trọng số cần được cập nhật để giảm chi phí dự đoán.
Ghi chú
Khái niệm lỗi tầng (layer error) ý chỉ đạo hàm của hàm chi phí theo đầu vào của một tầng trong mạng. Giá trị này giúp trả lời câu hỏi: Đầu ra của hàm chi phí thay đổi như thế nào khi đầu vào của tầng đó thay đổi?
Lỗi tầng đầu ra
Để tính lỗi tầng đầu ra, ta cần tìm đạo hàm hàm chi phí theo đầu vào của tầng đầu ra, \(Z_o\). Đạo hàm này (hay lỗi tầng đầu ra) giúp trả lời câu hỏi: các trọng số của tầng cuối cùng này ảnh hưởng thế nào lên lỗi của toàn mạng? Đạo hàm này được tính theo công thức:
Để đơn giản hoá phương trình trên, người ta thường ký hiệu biểu thức \((\hat{y}-y) * R'(Zo)\) bằng \(E_o\). Lúc này, phương trình tính lỗi tầng đầu ra có dạng:
Lỗi tầng ẩn
Để tính lỗi tầng của các tầng ẩn, ta cần tính đạo hàm hàm chi phí theo đầu vào của các tầng ẩn, \(Zh\).
Sau đó, ta có thể ký hiệu biểu thức trên thông qua \(E_o\) để đơn giản hoá phương trình tính lỗi tầng \(E_h\) cho các tầng ẩn.
Phương trình này là trọng tâm của kỹ thuật lan truyền ngược. Ta tính lỗi tầng hiện tại, đánh trọng số và truyền lỗi vừa tính về tầng phía trước, tiếp tục quá trình cho đến khi truyền tới tầng ẩn đầu tiên. Trong quá trình lan truyền, ta cập nhật các trọng số của từng tầng dựa theo đạo hàm hàm chi phí theo từng trọng số.
Đạo hàm của chi phí theo bất kỳ trọng số nào
Hãy quay trở lại với phương trình đạo hàm của hàm chi phí theo trọng số tại tầng đầu ra \(W_o\).
Ta biết rằng ta có thể thay vế đầu tiên trong phương trình bằng lỗi tầng đầu ra \(E_o\), với :math:`H`là kích hoạt tầng ẩn.
Do đó để tính đạo hàm của chi phí theo bất kỳ trọng số nào trong mạng, ta chỉ đơn giản nhân lỗi tầng của tầng tương ứng với đầu vào tại nơ-ron đó (tức là đầu ra của tầng phía trước).
Ghi chú
Đầu vào ám chỉ giá trị kích hoạt trả về bởi tầng trước đó, không phải là đầu vào được đánh trọng số \(Z\).
Tổng kết
Dưới đây là 3 phương trình mà cùng nhau tạo thành nền tảng của kỹ thuật lan truyền ngược.
Lỗi tầng đầu ra |
\(E_o = (O - y) \cdot R'(Z_o)\) |
Lỗi tầng ẩn |
\(E_h = E_o \cdot W_o \cdot R'(Z_h)\) |
Đạo hàm chi phí theo trọng số |
\(=\) Lỗi tầng \(\cdot\) Đầu vào |
Dưới đây là một ví dụ minh hoá quá trình trên sử dụng mô hình mạng nơ-ron đơn giản.
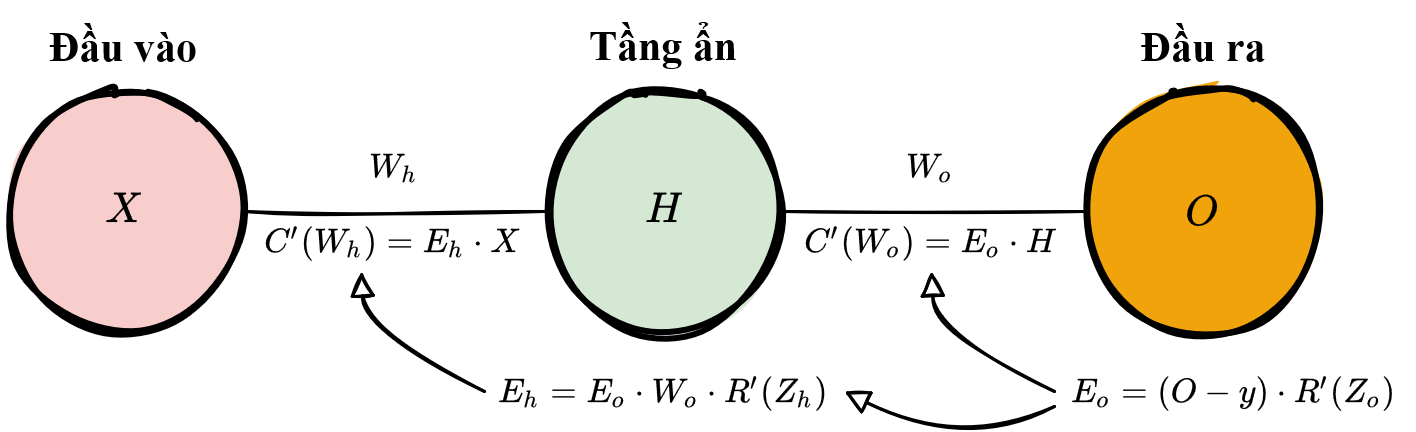
Ví dụ code¶
def relu_prime(z):
if z > 0:
return 1
return 0
def cost(yHat, y):
return 0.5 * (yHat - y)**2
def cost_prime(yHat, y):
return yHat - y
def backprop(x, y, Wh, Wo, lr):
yHat = feed_forward(x, Wh, Wo)
# Layer Error
Eo = (yHat - y) * relu_prime(Zo)
Eh = Eo * Wo * relu_prime(Zh)
# Cost derivative for weights
dWo = Eo * H
dWh = Eh * x
# Update weights
Wh -= lr * dWh
Tài liệu tham khảo
- 1
...