Các tầng đặc biệt trong mạng Nơ-ron¶
Tầng chuẩn hoá theo batch - BatchNorm¶
Tầng BatchNorm giúp tăng tốc độ hội tụ bằng cách giảm độ dịch hiệp biến nội bộ (internal covariate shift) 1 tại mỗi batch dữ liệu. Nếu từng quan sát đơn lẻ trong cùng một batch khác nhau đáng kể, việc cập nhật gradient sẽ không đều và khiến mô hình hội tụ lâu hơn.
Tầng chuẩn hoá theo batch sẽ chuẩn hoá toàn bộ kích hoạt của tầng trước nó và trả về một batch mới cho tầng sau với giá trị trung bình bằng \(0\) và độ lệch chuẩn \(1\). Về cơ bản, tầng này trừ giá trị trung bình và chia cho độ lệch chuẩn của batch đầu vào.
Code
Đoạn code tầng chuẩn hoá theo batch của Agustinus Kristiadi
def BatchNorm():
# From https://wiseodd.github.io/techblog/2016/07/04/batchnorm/
# TODO: Add doctring for variable names. Add momentum to init.
def __init__(self):
pass
def forward(self, X, gamma, beta):
mu = np.mean(X, axis=0)
var = np.var(X, axis=0)
X_norm = (X - mu) / np.sqrt(var + 1e-8)
out = gamma * X_norm + beta
cache = (X, X_norm, mu, var, gamma, beta)
return out, cache, mu, var
def backward(self, dout, cache):
X, X_norm, mu, var, gamma, beta = cache
N, D = X.shape
X_mu = X - mu
std_inv = 1. / np.sqrt(var + 1e-8)
dX_norm = dout * gamma
dvar = np.sum(dX_norm * X_mu, axis=0) * -.5 * std_inv**3
dmu = np.sum(dX_norm * -std_inv, axis=0) + dvar * np.mean(-2. * X_mu, axis=0)
dX = (dX_norm * std_inv) + (dvar * 2 * X_mu / N) + (dmu / N)
dgamma = np.sum(dout * X_norm, axis=0)
dbeta = np.sum(dout, axis=0)
return dX, dgamma, dbeta
Tài liệu đọc thêm
Tầng tích chập - Convolution¶
Trong mạng nơ-ron tích chập (Convolutional Neural Network - CNN), tích chập là một phép toán tuyến tính thực hiện việc nhân các trọng số (theo bộ lọc (filter/kernel)) với đầu vào. Tầng tích chập bao gồm 2 thành phần chính:
Bộ lọc - Kernel/Filters: Một tầng tích chập có thể có nhiều hơn một bộ lọc. Kích thước của một cửa sổ bộ lọc thường phải nhỏ hơn kích thước chiều dữ liệu đầu vào. Việc một bộ lọc được áp dụng nhiều lần lên nhiều vị trí khác nhau của đầu vào giúp mạng có thể hiểu được và xác định các đặc trưng quan trọng trong đầu vào dựa theo mối tương quan về mặt không gian (vị trí của các đặc trưng trong một quan sát). Bằng cách áp dụng nhiều cửa sổ bộ lọc khác nhau lên cùng một quan sát đầu vào, mạng có thể xác định được nhiều đặc trưng khác nhau trong dữ liệu đầu vào. Đầu ra của phép nhân bộ lọc với dữ liệu đầu vào là một mảng 2 chiều, và do đó, mảng tích chập đầu ra được gọi là "Ánh xạ đặc trưng - Feature Map".
Sải bước - Stride: Đây là siêu tham số quy định bước di chuyển của cửa sổ bộ lọc khi lần lượt được áp dụng vào dữ liệu đầu vào. Khi giá trị này được đặt bằng \(1\), cửa sổ bộ lọc sẽ di chuyển 1 cột (hay 1 hàng) mỗi lần trượt trên dữ liệu đầu vào; khi giá trị này được đặt bằng \(2\), cửa sổ bộ lọc sẽ di chuyển 2 cột (hay 2 hàng) mỗi lần trượt trên dữ liệu đầu vào.

Minh hoạ bộ lọc \(1 \times 3\) trượt trên đầu vào với sải bước \(S=2\)¶
Code
# this code demonstate on how Convolution works
# Assume we have a image of 4 X 4 and a filter fo 2 X 2 and Stride = 1
def conv_filter_ouput(input_img_section,filter_value):
# this method perfromas the multiplication of input and filter
# returns singular value
value = 0
for i in range(len(filter_value)):
for j in range(len(filter_value[0])):
value = value + (input_img_section[i][j]*filter_value[i][j])
return value
img_input = [[260.745, 261.332, 112.27 , 262.351],
[260.302, 208.802, 139.05 , 230.709],
[261.775, 93.73 , 166.118, 122.847],
[259.56 , 232.038, 262.351, 228.937]]
filter = [[1,0],
[0,1]]
filterX,filterY = len(filter),len(filter[0])
filtered_result = []
for i in range(0,len(img_mx)-filterX+1):
clm = []
for j in range(0,len(img_mx[0])-filterY+1):
clm.append(conv_filter_ouput(img_mx[i:i+filterX,j:j+filterY],filter))
filtered_result.append(clm)
print(filtered_result)
Tài liệu đọc thêm
Tầng Dropout¶
Một tầng dropout nhận đầu ra kích hoạt của tầng trước đó và đặt ngẫu nhiên một tỉ lệ nhất định (dựa theo tỉ lệ dropout) các kích hoạt đó về \(0\), nhằm "tắt" các kích hoạt đó đi.
Đây là một kỹ thuật điều chuẩn khá phổ biến được sử dụng trong mạng nơ-ron để hạn chế hiện tượng quá khớp.
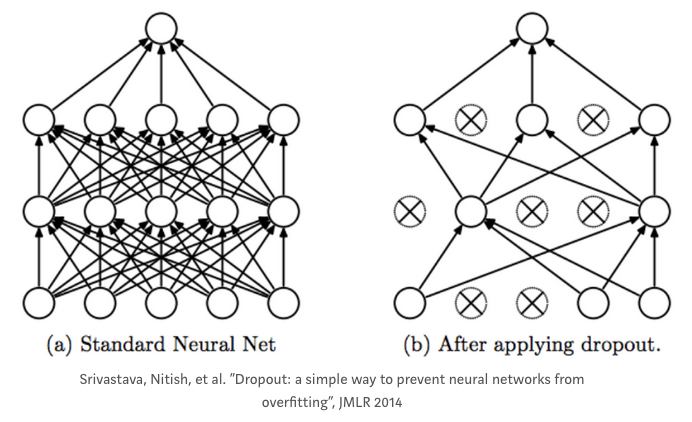
Tỉ lệ dropout là một siêu tham số có thể được tinh chỉnh, thường sẽ nhận giá trị trong khoảng \(0.2\) đến \(0.5\) (nhưng cũng có thể là một giá trị bất kỳ nào khác).
Dropout thường chỉ được sử dụng trong quá trình huấn luyện. Khi thực hiện suy luận hay dự đoán trên tập kiểm tra, sẽ không có bất cứ kích hoạt nào bị tắt, mà các kích hoạt sẽ bị giảm đi qua việc nhân với tỉ lệ dropout. Việc giảm các kích hoạt đi là cần thiết do có nhiều đơn vị nơ-ron hoạt động hơn khi thực hiện dự đoán so với quá trình huấn luyện mạng.
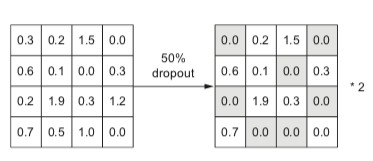
Ví dụ về phương thức hoạt động của tầng dropout:
Một tầng trong mạng nơ-ron trả về một tensor (ma trận) \(A\) có kích thước (batch_size, num_features).
Tỉ lệ dropout của tầng này được đặt bằng \(0.5\) (\(50\%\)).
Ngẫu nhiên \(50\%\) các giá trị của ma trận \(A\) sẽ bị gán bằng \(0\).
Các kích hoạt còn lại sẽ được nhân với ma trận trọng số khi được truyền tới tầng tiếp theo.
Để giải thích cách hoạt động của tầng dropout, nhiều nhà nghiên cứu giả thuyết rằng cơ chế tắt ngẫu nhiên của tầng dropout giúp đưa nhiễu vào một tầng để phá vỡ các hình mẫu không đáng có được học qua sự phụ thuộc lẫn nhau giữa các đơn vị trong cùng 1 tầng.
Code
# layer_output is a 2D numpy matrix of activations
layer_output *= np.random.randint(0, high=2, size=layer_output.shape) # dropping out values
# scaling up by dropout rate during TRAINING time, so no scaling needs to be done at test time
layer_output /= 0.5
# OR
layer_output *= 0.5 # Scaling down during TEST time.
Đoạn code trên minh hoạ cho thao tác sau 3.
Tầng gộp - Pooling¶
Tầng gộp, hay tầng Pooling, thường lấy đầu ra của các tầng tích chập làm đầu vào. Một tập dữ liệu phức tạp có rất nhiều đối tượng sẽ yêu cầu một số lượng lớn các bộ lọc, mỗi bộ lọc có nhiệm vụ tìm các hình mẫu khác nhau trong ảnh, và do đó kích thước đầu ra của tầng tích chập có thể khá lớn. Việc này sẽ làm tăng số tham số mô hình, và có thể dẫn đến hiện tượng quá khớp. Các tầng gộp được áp dụng để giảm kích thước chiều của tầng tích chập đi.
Giống như tầng tích chập, tầng gộp có 2 thành phần chính là kích thước cửa sổ bộ lọc và bước sải. Kích thước của bộ lọc cần phải nhỏ hơn kích thước ánh xạ đặc trưng. Trong đa số các trường hợp, kích thước bộ lọc của tầng gộp sẽ bằng \(2 \times 2\) với sải bước bằng \(2\).
Có 2 loại tầng gộp phổ biến. Loại đầu tiên là tầng gộp cực đại (max pooling). Tầng gộp cực đại sẽ lấy các ánh xạ đặc trưng (trả về bởi tầng tích chập) làm đầu vào, và giá trị trả về bởi tầng tại mỗi vị trí cửa sổ sẽ là giá trị cực đại của các điểm giá trị nằm trong cửa sổ bộ lọc.
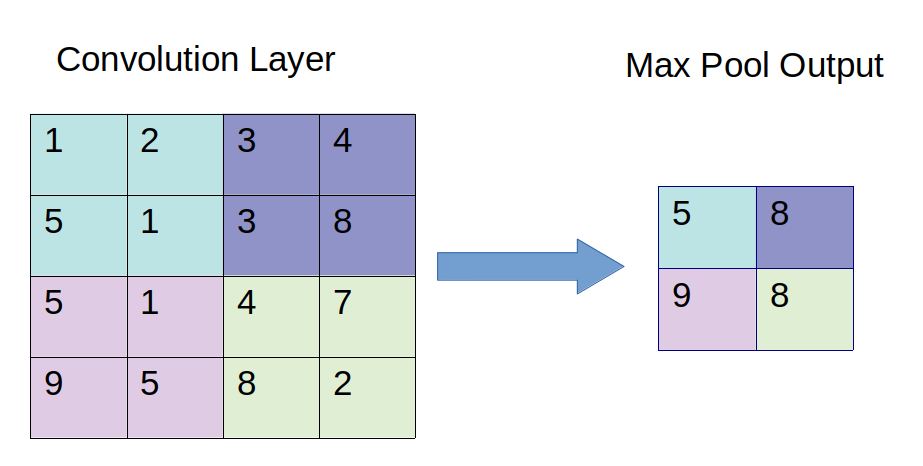
Minh hoạ tầng gộp cực đại, với kích thước bộ lọc \(2 \times 2\) và sải bước bằng \(2\)¶
Một loại tầng gộp khác là tầng gộp trung bình (average pooling). Tầng gộp trung bình sẽ tính trung bình các giá trị nằm trong cửa sổ bộ lọc. Loại này không được ứng dụng phổ biến bằng tầng gộp cực đại, bạn sẽ thường bắt gặp nó trong các ứng dụng mà có yêu cầu làm mịn ảnh.
Code
def max_pooling(feature_map, size=2, stride=2):
"""
:param feature_map: Feature matrix of shape (height, width, layers)
:param size: size of kernal
:param stride: movement speed of kernal
:return: max-pooled feature vector
"""
pool_shape = (feature_map.shape[0]//stride, feature_map.shape[1]//stride, feature_map.shape[-1]) #shape of output
pool_out = numpy.zeros(pool_shape)
for layer in range(feature_map.shape[-1]):
#for each layer
row = 0
for r in numpy.arange(0,feature_map.shape[0], stride):
col = 0
for c in numpy.arange(0, feature_map.shape[1], stride):
pool_out[row, col, layer] = numpy.max([feature_map[c:c+size, r:r+size, layer]])
col = col + 1
row = row +1
return pool_out
Khối mạng nơ-ron Hồi tiếp - RNN¶
Mạng nơ-ron hồi tiếp (Recurrent Neural Network) là một mạng nơ-ron với các trạng thái ẩn nắm giữ thông tin trong quá khứ của dữ liệu hiện tại. Do trạng thái ẩn của trạng thái hiện tại mang gần như cùng 1 ý nghĩa so với dữ liệu tại bước thời gian trước đó, việc tính toán trong mạng có thể được coi là hồi tiếp, và do đó có tên gọi là mạng nơ-ron hồi tiếp.
Kiến trúc của một khối mạng nơ-ron hồi tiếp như sau:
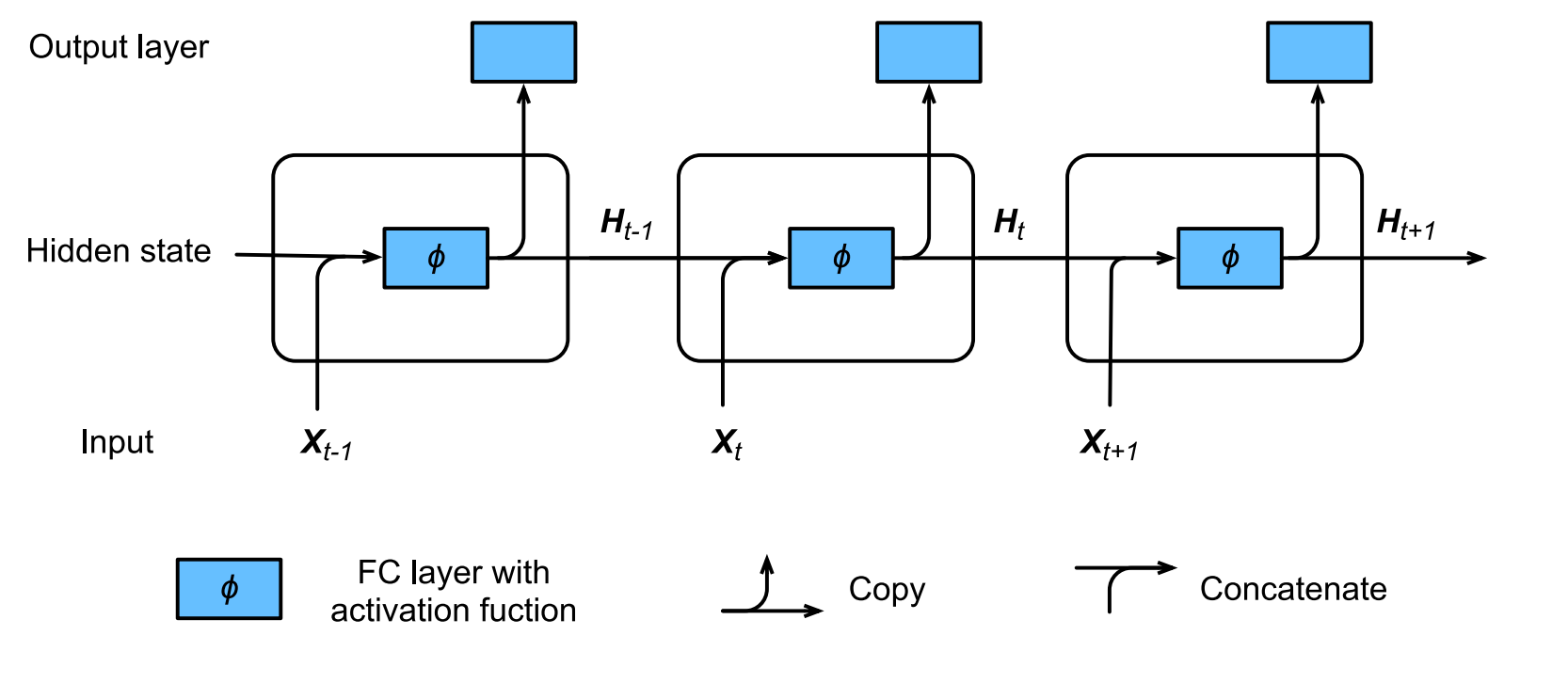
Code 4
class RNN:
def __init__(self, input_dim: int, hidden_dim: int, output_dim: int, batch_size=1) -> None:
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.out_dim = output_dim
self.batch_size = batch_size
# initialization
self.params = self._init_params()
self.hidden_state = self._init_hidden_state()
def _init_params(self) -> List[np.array]:
scale = 0.01
Waa = np.random.normal(scale=scale, size=[self.hidden_dim, self.hidden_dim])
Wax = np.random.normal(scale=scale, size=[self.hidden_dim, self.input_dim])
Wy = np.random.normal(scale=scale, size=[self.out_dim, self.hidden_dim])
ba = np.zeros(shape=[self.hidden_dim, 1])
by = np.zeros(shape=[self.out_dim, 1])
return [Waa, Wax, Wy, ba, by]
def _init_hidden_state(self) -> np.array:
return np.zeros(shape=[self.hidden_dim, self.batch_size])
def forward(self, input_vector: np.array) -> np.array:
"""
input_vector:
dimension: [num_steps, self.input_dim, self.batch_size]
out_vector:
dimension: [num_steps, self.output_dim, self.batch_size]
"""
Waa, Wax, Wy, ba, by = self.params
output_vector = []
for vector in input_vector:
self.hidden_state = np.tanh(
np.dot(Waa, self.hidden_state) + np.dot(Wax, vector) + ba
)
y = softmax(
np.dot(Wy, self.hidden_state) + by
)
output_vector.append(y)
return np.array(output_vector)
if __name__ == "__main__":
input_data = np.array([
[
[1, 3]
, [2, 4]
, [3, 6]
]
, [
[4, 3]
, [3, 4]
, [1, 5]
]
])
batch_size = 2
input_dim = 3
output_dim = 4
hidden_dim = 5
time_step = 2
rnn = RNN(input_dim=input_dim, batch_size=batch_size, output_dim=output_dim, hidden_dim=hidden_dim)
output_vector = rnn.forward(input_vector=input_data)
print("RNN:")
print(f"Kích thước dữ liệu đầu vào: {input_data.shape}")
print(f"Kích thước dữ liệu đầu ra: {output_vector.shape}")
## Kết quả:
## RNN:
## Kích thước dữ liệu đầu vào: (2, 3, 2)
## Kích thước dữ liệu đầu ra: (2, 4, 2)
Nút Hồi tiếp có Cổng - GRU¶
Nút hồi tiếp có cổng (Gated Recurrent Unit) hỗ trợ kiểm soát các trạng thái ẩn của khối hồi tiếp:
Cổng xoá (Reset gate) kiểm soát bao nhiêu phần của trạng thái ẩn trước mà ta vẫn muốn nhớ.
Cổng cập nhật (Update gate) kiểm soát bao nhiêu phần của trạng thái hiện tại giống hệt với trạng thái trước đó.
Kiến trúc GRU và các công thức toán học có dạng như sau:

Code 4
class GRU:
def __init__(self, input_dim: int, hidden_dim: int, output_dim: int, batch_size=1) -> None:
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.out_dim = output_dim
self.batch_size = batch_size
# initialization
self.params = self._init_params()
self.hidden_state = self._init_hidden_state()
def _init_params(self) -> List[np.array]:
scale = 0.01
def param_single_layer():
w = np.random.normal(scale=scale, size=(self.hidden_dim, self.hidden_dim+input_dim))
b = np.zeros(shape=[self.hidden_dim, 1])
return w, b
# reset, update gate
Wr, br = param_single_layer()
Wu, bu = param_single_layer()
# output layer
Wy = np.random.normal(scale=scale, size=[self.out_dim, self.hidden_dim])
by = np.zeros(shape=[self.out_dim, 1])
return [Wr, br, Wu, bu, Wy, by]
def _init_hidden_state(self) -> np.array:
return np.zeros(shape=[self.hidden_dim, self.batch_size])
def forward(self, input_vector: np.array) -> np.array:
"""
input_vector:
dimension: [num_steps, self.input_dim, self.batch_size]
out_vector:
dimension: [num_steps, self.output_dim, self.batch_size]
"""
Wr, br, Wu, bu, Wy, by = self.params
output_vector = []
for vector in input_vector:
# expit in scipy is sigmoid function
reset_gate = expit(
np.dot(Wr, np.concatenate([self.hidden_state, vector], axis=0)) + br
)
update_gate = expit(
np.dot(Wu, np.concatenate([self.hidden_state, vector], axis=0)) + bu
)
candidate_hidden = np.tanh(
reset_gate * self.hidden_state
)
self.hidden_state = update_gate * self.hidden_state + (1-update_gate) * candidate_hidden
y = softmax(
np.dot(Wy, self.hidden_state) + by
)
output_vector.append(y)
return np.array(output_vector)
Khối nhớ Ngắn hạn Dài - LSTM¶
Để có thể giải quyết bài toán lưu trữ thông tin dài hạn và bỏ qua đầu vào ngắn hạn trong các mô hình sử dụng trạng thái ẩn (ví dụ như RNN), Khối nhớ Ngắn hạn Dài (Long short-term Memory) được giới thiệu. Trong LSTM, các ô nhớ có cùng kích thước với trạng thái ẩn, tức là có thể coi như một phiên bản phức tạp hơn của một trạng thái ẩn, được thiết kế để ghi lại các thông tin cần thiết.
Kiến trúc khối LSTM và các công thức toán học có dạng như sau:
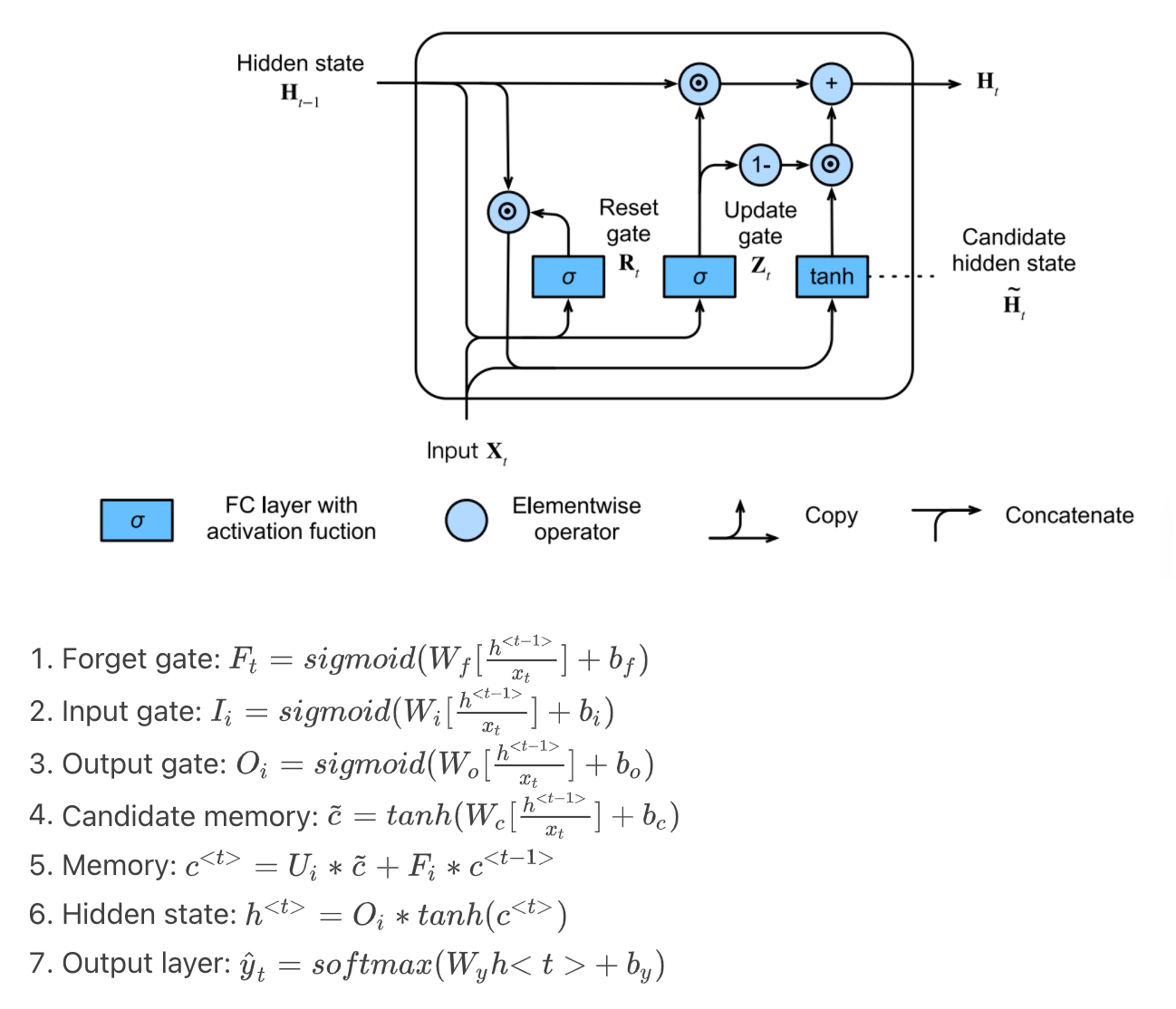
Code 4
class LSTM:
def __init__(self, input_dim: int, hidden_dim: int, output_dim: int, batch_size=1) -> None:
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.out_dim = output_dim
self.batch_size = batch_size
# initialization
self.params = self._init_params()
self.hidden_state = self._init_hidden_state()
self.memory_state = self._init_hidden_state()
def _init_params(self) -> List[np.array]:
scale = 0.01
def param_single_layer():
w = np.random.normal(scale=scale, size=(self.hidden_dim, self.hidden_dim+input_dim))
b = np.zeros(shape=[self.hidden_dim, 1])
return w, b
# forget, input, output gate + candidate memory state
Wf, bf = param_single_layer()
Wi, bi = param_single_layer()
Wo, bo = param_single_layer()
Wc, bc = param_single_layer()
# output layer
Wy = np.random.normal(scale=scale, size=[self.out_dim, self.hidden_dim])
by = np.zeros(shape=[self.out_dim, 1])
return [Wf, bf, Wi, bi, Wo, bo, Wc, bc, Wy, by]
def _init_hidden_state(self) -> np.array:
return np.zeros(shape=[self.hidden_dim, self.batch_size])
def forward(self, input_vector: np.array) -> np.array:
"""
input_vector:
dimension: [num_steps, self.input_dim, self.batch_size]
out_vector:
dimension: [num_steps, self.output_dim, self.batch_size]
"""
Wf, bf, Wi, bi, Wo, bo, Wc, bc, Wy, by = self.params
output_vector = []
for vector in input_vector:
# expit in scipy is sigmoid function
foget_gate = expit(
np.dot(Wf, np.concatenate([self.hidden_state, vector], axis=0)) + bf
)
input_gate = expit(
np.dot(Wi, np.concatenate([self.hidden_state, vector], axis=0)) + bi
)
output_gate = expit(
np.dot(Wo, np.concatenate([self.hidden_state, vector], axis=0)) + bo
)
candidate_memory = np.tanh(
np.dot(Wc, np.concatenate([self.hidden_state, vector], axis=0)) + bc
)
self.memory_state = foget_gate * self.memory_state + input_gate * candidate_memory
self.hidden_state = output_gate * np.tanh(self.memory_state)
y = softmax(
np.dot(Wy, self.hidden_state) + by
)
output_vector.append(y)
return np.array(output_vector)
Tài liệu tham khảo
- 1
- 2
- 3
“4.4.3, Fundamentals of Machine Learning: Adding Dropout.” Deep Learning for Python, by Chollet, François. Manning Publications Co., 2018, pp. 109–110.
- 4(1,2,3)
`Dive into Deep Learning https://d2l.ai/index.html`_, by Zhang, Aston and Lipton, Zachary C. and Li, Mu and Smola, Alexander J.